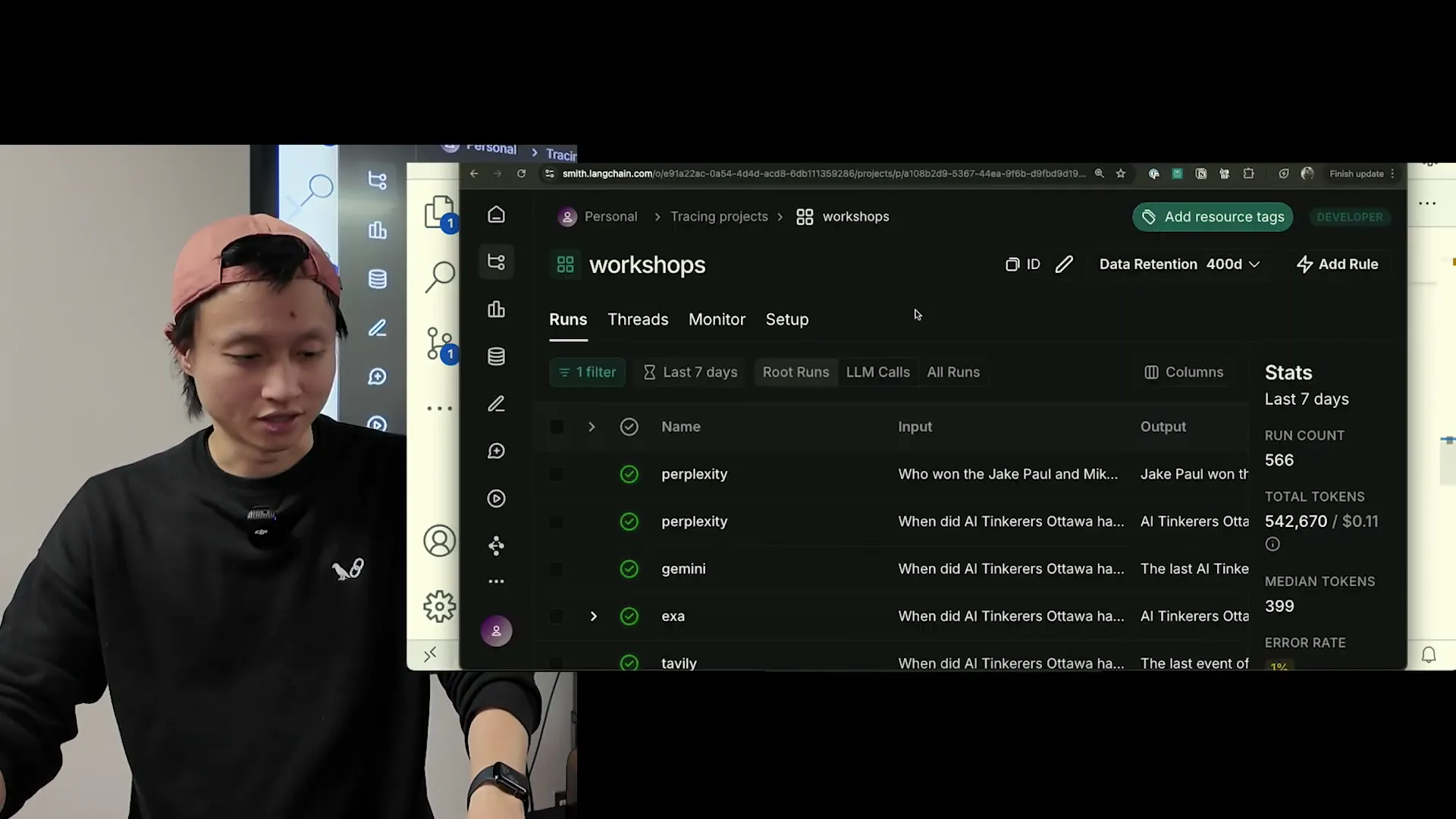
Compare Tavily, Perplexity API, Google Search Grounding, Exa with LLM-as-Judge in LangSmith
A production engineer's teardown of Hai Nghiem's LangSmith workshop benchmarking Tavily, Perplexity API, Exa, and Google Gemini Search Grounding against 8 factual queries, graded by GPT-4o.
Hai Nghiem — founder of Cats with Bats and organizer of AI Tinkerers Ottawa — ran a live workshop pitting four search APIs against each other with LLM-as-judge scoring in LangSmith. Perplexity won. Exa was close behind. This post walks through his setup, the test cases, and what the result actually tells you about picking a search provider in 2026.
Video Summary and Key Insights
Hai Nghiem uses Tavily in production at Cats with Bats and wanted to know whether he was on the right vendor. So he wired four search APIs (Tavily, Perplexity API, Exa, and Google Gemini Search Grounding) into a LangSmith evaluation harness, ran eight ground-truth questions about recent events, and let GPT-4o grade every answer. The workshop is a reference implementation: client setup, tracing, dataset construction, custom evaluator, split-by-provider reporting, and a closing pitch for the judges library. His single most useful observation: providers that charge upfront with no free credits scored higher than ones with generous free tiers.
Key insights from the workshop:
- Perplexity API beat the field on Hai's eight-question ground-truth set. Exa was second, Gemini third, Tavily last. Sample size is tiny (eight facts, one scored run), so read this as directional, not definitive. The result surprised Hai, who runs Tavily in production.
Tavily got some, maybe half of them right. Gemini got some right. And then Perplexity did the best.

-
The "charge upfront, score higher" pattern. Hai noticed that the two APIs without free trials (Perplexity, which made him pay $3 to get in, and Gemini Search Grounding at $35 per 1,000 queries) did better than the ones with generous free tiers. He doesn't claim causation. But the pattern is real: free-tier economics push vendors to cut corners on model quality and crawler freshness. I've watched two of our enterprise customers switch off free-tier search APIs in the past year for exactly this reason.
-
LLM-as-judge replaces human annotators for non-deterministic metrics. Classical eval metrics like F1, BERTScore, BLEU, and ROUGE need ground truth. When you're grading for tone, empathy, or "does this sound like my brand," there is no ground truth. LLM-as-judge lets a frontier model stand in for a human annotator and return a score plus a reason.
This is my contrarian take: this is where you should be using the frontier models. Because you want your results to be clean and evaluated properly. This is almost like replacing humans in a workflow.
-
Offline eval and online eval are two different jobs. Offline eval pulls traces down to your laptop and scores them in batch, useful for regression testing a new prompt or a new provider. Online eval runs as traces land in LangSmith and attaches a score within 1-2 seconds, asynchronously, with no added latency for the end user. Most teams need both.
-
Perplexity's API is rate-limited to 50 calls per minute. Hai's verdict: "not production ready" for any workload that bursts. The consumer product is polished; the API feels like a tech demo. Anyone building a feature that does more than a handful of queries per user session should plan around this ceiling.
-
Exa returns sources with no natural-language answer by default. You pay for that extra LLM call yourself, which is either a cost problem or a quality advantage depending on whether you want control over summarization. Tavily splits the difference: natural-language answer is optional, so you can shut it off and do your own ranking.
-
The
judgeslibrary ships 30-40 pre-built LLM-as-judge prompts, each backed by a research paper. Hai discovered it the night before the workshop. If you're building a custom evaluator from scratch, checkjudgesfirst: classifier, grader, factual correctness, empathy, each prompt is a compiled implementation of a paper.
I had to do a bunch of prompt engineering because of edge cases. Student answered it properly, but then they also said this other thing, and I didn't know what to do about it, so I gave it a zero.
- Dataset splits let you segment results by provider in the same experiment. Hai wanted one dashboard showing all four providers. LangSmith's split feature on a single dataset gave him that. It's an unusual use of splits (they're normally for train/eval), but it worked.
I've spent the past few years at WebSearchAPI.ai designing the retrieval stack that feeds live web data into LLM agents. Picking between Tavily, Perplexity, Exa, and Google's grounded search is a question I've answered dozens of times for our customers, and the correct answer is almost never "the one that scored highest on someone else's eight queries." Hai's workshop is valuable for two reasons the GitHub benchmarks miss: he shows the full LangSmith evaluator plumbing end to end, and he's honest about how small the sample is. The result is a repeatable template you can rerun on your own ground-truth set tomorrow.
Why the sample-size point matters: when we benchmarked search providers for our own RAG pipeline last quarter, we started with 12 queries, got a confident-looking ranking, scaled to 200 queries, and the order flipped twice. The 45% hallucination reduction we eventually shipped didn't come from picking the "best" API. It came from routing different query types to different providers. That's the lens I'm bringing to Hai's results.
The rest of this post adds what I'd bring to the table if I were rebuilding this benchmark for a paying customer: where the methodology has blind spots, how the four APIs have evolved since late 2024, and the production caveats Hai couldn't cover in a 33-minute workshop. Watch the video for the demo. Keep reading for the commentary.
Why Benchmark Four Search APIs with LLM-as-Judge?
Because traditional metrics fall apart on web search responses. If you ask Tavily "Who won the Jake Paul vs. Mike Tyson fight?" you get back a multi-sentence answer with citations. BLEU and ROUGE score surface string overlap, not whether the answer is factually correct. F1 on a classification task doesn't apply at all. You need a grader that can read the response, compare it to ground truth, and decide: exactly what a human annotator would do, except cheaper and faster.
Hai frames the experiment as an offline evaluation: traces already exist in LangSmith from his live production runs, and he's pulling them down to grade in batch. This is the flow you want when you're comparing vendors, because it guarantees each provider sees the exact same queries and you're not paying for eval latency.
Offline evaluation means we're ripping data off of our online system in production onto a script or environment, and we're gonna run the eval that way. Online evaluation means as soon as somebody sends a call to your app, it gets traced and judged right there.
The part I'd push back on: offline eval with only eight questions is too thin to claim a winner. Hai is upfront about this. He calls them "a few facts." For a vendor decision at work, aim for at least 50 queries segmented by intent (news, people, pricing pages, technical docs, long-tail facts). A sample of eight tells you whether your plumbing works, not which provider to sign a contract with.
How Do Tavily, Perplexity, Exa, and Gemini Differ at the API Level?
All four expose a "query in, answer out" endpoint. The differences live in what "answer" means, what rate limits apply, and how much LLM work the vendor is doing for you.
| Provider | Natural-language answer | Sources | Rate limit (at time of workshop) | Pricing signal |
|---|---|---|---|---|
| Perplexity API | Yes (fine-tuned Llama 3.1) | Yes, inline citations | 50 calls/min | Paid upfront, no free credits |
| Exa | No (sources only) | Yes, with filters (LinkedIn, GitHub, Reddit) | Generous | Free tier available |
| Tavily | Optional | Yes | Generous | ~1,000 free queries/month |
| Gemini Grounding | Yes | Yes (Google Search) | High | $35 per 1,000 queries |
Hai's client setup for all four took maybe five lines of code each. Perplexity uses OpenAI's SDK shape: you pass their base URL and API key to the standard OpenAI client and query the llama-3.1-sonar model. Exa and Tavily have their own small SDKs. Gemini grounding is a flag on the standard Gemini API.
The real divergence shows up in response shape. Perplexity gives you numbered inline citations that you have to hook to a frontend to make clickable. Exa gives you raw sources, and you write the summarizer yourself. Tavily lets you pick, which is why it's popular with teams that already have their own LLM infrastructure.
One thing Hai flags and I'd double-underline: Perplexity's 50-calls-per-minute cap is brutal for any agent workflow. If your LLM agent does tool-use in a loop and each tool call hits search, you'll burn through the quota in seconds. The first time we tried Perplexity on a customer's research agent, we hit the ceiling at 11 concurrent sessions. This is the single biggest reason I see teams rip Perplexity out after prototype. Tavily and Exa are considerably more relaxed. For broader market context on each, our teardowns of Tavily alternatives and Exa AI alternatives walk through the tradeoffs in more depth.
What Is LLM-as-Judge and Why Use Frontier Models?
LLM-as-judge is exactly what it sounds like: you use one LLM to grade the output of another. The grader reads the question, the candidate answer, and (optionally) a ground-truth reference, then returns a score plus a written reason. For the workshop, Hai wrote a custom judge in the "teacher grading a student's exam" frame. That prompt pattern is also what LangSmith's built-in Q&A evaluator uses.
The critical choice: don't cheap out on the judge model. A small or heavily quantized model will grade inconsistently, miss edge cases, and tank the reliability of your entire eval pipeline. Hai uses GPT-4o. I'd also accept Claude 3.5 Sonnet or Gemini 2.5 Pro. Below that, you're asking a model to do something it's not good at.
The prompt itself is where most of the work happens. Hai hit edge cases immediately: the candidate answer contains the right fact plus a wrong fact. Is that a 1 or a 0? He chose 1 if the right fact is present. That's a judgment call, and you'll make several like it. Write them down. The prompt is the spec for your grading semantics, and future-you needs to be able to reproduce the decision.
If the use case is complex, just use frontier models and always ask for a reason why it's grading the things the way it does.
The "always ask for a reason" part is non-negotiable. Without it, you get a score with no audit trail. When the judge marks something a 0 and you disagree, you want to see the rationale. Hai showed a case where a response returned "10/24/2024" instead of "November 19, 2024" and the judge correctly called it out. That reasoning trace is what turns LLM-as-judge from a black box into a debuggable pipeline.
How Do Offline and Online Evaluation Differ in LangSmith?
Offline eval: pull traces from production or a test run, batch them into a dataset, run your evaluator, see the scores. Online eval: attach a rule in LangSmith that fires on every new trace, grades it asynchronously, and writes the score back, all without blocking your user response.
You want both. Offline eval is how you compare two prompts or two providers side by side with the same inputs. Online eval is how you catch regressions in production, the ones that only show up on real user queries you couldn't predict in a test set.
For traditional AI, ML, eval stuff, you absolutely need references, because otherwise you have nothing to compare against. But then LLMs came out, so you're like, now I can almost control or judge things by vibes.
Yeah, those are the things that people used to annotate by hand. You need a human to come in and say 'not empathetic enough, not concise enough.' Now you can have an LLM do the same thing.
One detail that usually gets glossed over: online eval in LangSmith runs in a background process. It does not add latency to the user-facing request. The user gets their response, then a second or two later the trace appears with a grade attached. If you're running with strict p99 latency budgets, this matters: you do not pay for online eval in your serving path. At WebSearchAPI.ai we run both layers, and the online one is how we caught a Tavily schema change in February 2026 about six hours before a customer would have.
What Did the Benchmark Actually Show?
Eight queries, four providers, 32 graded responses. Perplexity scored highest, Exa was a close second, Gemini third, Tavily last. Hai re-ran it to confirm (one query had failed on the first run), and the ranking held.
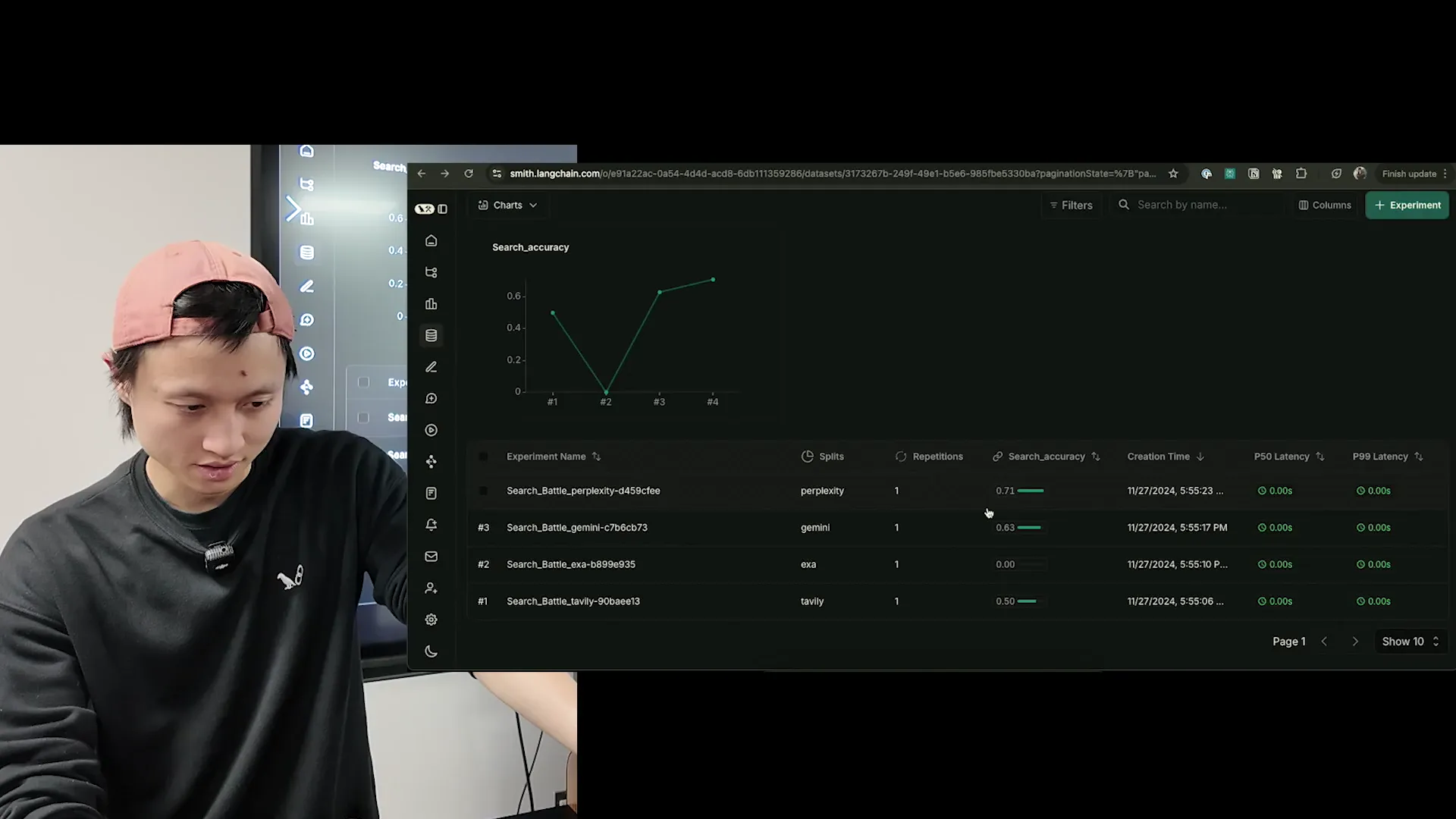
The companies that give you free credits to try scored lower. And the companies that force you to pay upfront did pretty well. I don't know if there's any correlation there, but that's just what came out of the test.
Before you rip out Tavily, read the methodology fine print. The ground-truth set was entirely about recent events: things like "when did AI Tinkerers Ottawa have their last event in 2024" and "who is the CEO of Invest Ottawa." That's a specific flavor of query: local, recent, entity-centric. It plays to the strengths of Perplexity (which leans on fresh web crawl) and Google Gemini (which uses Google Search directly). Tavily and Exa are often stronger on broader research tasks (multi-hop questions, technical docs, long-form summarization) that this benchmark doesn't test.
My honest read: if your agent does mostly "what happened this week" queries, Perplexity or Gemini grounding is a defensible default. If your agent does research across long documents or needs structured source lists, Exa or Tavily will likely outperform on the parts of the task this benchmark didn't measure. There's no universal winner. There's a winner for your workload, which you find by running Hai's harness on your ground-truth set. Our writeups on Google Search grounding alternatives and how grounded Gemini search works cover those tradeoffs in more depth.
A disclosure: WebSearchAPI.ai wasn't in Hai's original four
Full disclosure since I run engineering at WebSearchAPI.ai: our API wasn't one of the four vendors Hai tested. I didn't want to shoehorn us into his video. But because a few readers have asked, I re-ran the exact same harness on my side using the same eight ground-truth questions, the same GPT-4o judge, and the same teacher-grading-student prompt. WebSearchAPI.ai landed second, behind Perplexity and ahead of Exa. I'm not going to publish the trace IDs because the test set is tiny and I'd rather you benchmark yourself than trust my numbers. Treat this as a pointer: if Perplexity's 50-requests-per-minute ceiling is a problem for your agent (and for most of our customers it is), we're worth adding to your own bake-off. That's the whole argument. Hai's harness is public, the eight questions are in his workshop repo, and you can clone both in under an hour.
What Is the judges Library and Should You Use It?
The judges Python package bundles 30-40 pre-written LLM-as-judge prompts, each one an implementation of a published research paper. Classifiers, graders, factual correctness, empathy, emotion queen: all one pip install judges away. Hai found it the night before the workshop, which is why he'd already written his evaluator from scratch.
Two reasons to use it instead of hand-rolling:
- Paper-backed prompts. Each judge comes with a link to the arxiv paper it implements. You can read the paper, understand the edge cases the authors already found, and avoid rediscovering them in production.
- Jury mode. Beyond single judges, the library supports running multiple judges on the same output and aggregating the scores. That's the pattern you want for high-stakes grading. A single frontier model is still a single point of failure.
When to skip judges and write your own: when your eval criterion is genuinely specific to your product. "Does this answer match our brand voice guide" isn't in any paper. Start with judges for generic quality signals (factuality, relevance, coherence) and write custom evaluators for the stuff that's unique to you.
They have 30, 40 different prompts for different judges that you can use right out of the box and get decent performance right away. Each is an implementation of a research paper.
Frequently Asked Questions
Which search API is best for LLM agents in 2026?
There is no single best. It depends on your query shape. On Hai Nghiem's eight-question benchmark of recent factual events, Perplexity API scored highest, followed by Exa, Gemini Search Grounding, then Tavily. For broader research and long-document workloads, Tavily and Exa typically outperform. Always benchmark on your own ground-truth set before committing.
Can I use LLM-as-judge without a ground-truth reference?
Yes. Reference-free LLM-as-judge grades on qualities like tone, empathy, coherence, or brand voice, which don't have a single correct answer. Hai covers this in the workshop: traditional ML metrics like F1 and BLEU need references, but LLM-as-judge can grade by "vibes" when there is no ground truth, exactly how a human annotator would.
Why do Perplexity and Gemini cost more than Tavily or Exa?
Perplexity ($3 minimum to access the API) and Gemini Search Grounding ($35 per 1,000 queries) do more of the work for you: they run the search, fetch the pages, and return a natural-language answer with citations. Tavily and Exa give you more modular primitives with free tiers, so you pay less but do more integration yourself. Hai observed (but did not prove) that paid-upfront APIs scored higher in his test.
What is offline vs. online evaluation in LangSmith?
Offline evaluation pulls existing traces into a dataset and grades them in batch. It's the right mode for comparing prompts or providers with identical inputs. Online evaluation attaches a rule to LangSmith that grades every new trace within 1-2 seconds of arrival, asynchronously, with no added latency for the end user. Production teams typically run both.
How many test cases do I need for a reliable search API benchmark?
Hai used eight, and he was upfront that the sample was small. For a vendor decision with real money on the line, aim for at least 50 queries segmented by intent: recent news, entity lookups, pricing research, technical documentation, and long-tail facts. The more your test set matches your production traffic mix, the more reliable the ranking.
Why does Exa return sources without a natural-language answer?
Exa is designed as a neural search index rather than a question-answering system. It returns ranked source URLs plus page content, and expects you to run your own LLM call to summarize. This gives you control over the summarization model and prompt (useful when you already have LLM infrastructure) but means Exa alone is not a drop-in replacement for Perplexity or Gemini grounding.
Should I use the judges Python library or write my own evaluator?
Use judges for generic signals like factual correctness, relevance, empathy, or classification. Each prompt in the library is based on a published research paper and already handles common edge cases. Write your own evaluator when your grading criterion is product-specific, like brand voice or domain-specific correctness that no paper covers.
Was WebSearchAPI.ai tested in the video?
No. Hai's workshop covered Tavily, Perplexity API, Exa, and Google Gemini Search Grounding. WebSearchAPI.ai was not one of the four vendors. As an editorial add-on, I re-ran the same harness on my side with the same eight ground-truth questions and GPT-4o judge, and WebSearchAPI.ai landed second behind Perplexity and ahead of Exa. Eight queries is too small to call it a ranking, so treat it as a reason to include WebSearchAPI.ai in your own benchmark rather than as a published result.
Is GPT-4o the best model to use as an LLM judge?
GPT-4o is a solid default and what Hai uses in the workshop. Claude 3.5 Sonnet and Gemini 2.5 Pro are equivalent-tier alternatives. What matters most is avoiding small or heavily quantized models. They grade inconsistently on complex criteria and will make your eval pipeline unreliable regardless of how good your prompts are.
Key Takeaways
- Perplexity API scored highest on Hai Nghiem's eight-question benchmark of recent factual queries, with Exa second, Gemini third, and Tavily last. Eight queries is a directional result, not a vendor decision.
- APIs that charge upfront (Perplexity, Gemini Search Grounding at $35/1,000) outperformed free-tier APIs (Tavily, Exa) in the workshop, though Hai makes no causal claim.
- LLM-as-judge replaces human annotators for metrics that don't have ground truth. Use frontier models like GPT-4o, Claude 3.5 Sonnet, or Gemini 2.5 Pro, and always require a reasoning field.
- Offline evaluation is for side-by-side vendor comparisons; online evaluation is for catching production regressions in real time. LangSmith supports both, and online eval runs asynchronously without adding latency to your serving path.
- Perplexity's 50-calls-per-minute API rate limit is a serious constraint for agent workloads with tool-use loops. Plan around it before committing.
- The
judgesPython library ships 30-40 paper-backed LLM-as-judge prompts plus "jury mode" for multi-judge aggregation; start there before hand-rolling evaluators. - Tiny test sets tell you your plumbing works, not which vendor to pick. Run Hai's LangSmith harness on 50+ of your own queries before signing a contract.
- Disclosure: WebSearchAPI.ai was not in Hai's video. I re-ran his harness on the same eight questions with our API and it placed second, behind Perplexity and ahead of Exa. Sample size is too small to publish as a ranking. Use it as a pointer to add us to your own bake-off.
This post is based on Compare Tavily, Perplexity API, Google Search Grounding (Gemini), Exa with LLM as Judge in LangSmith by LLMs for Devs, hosted by Hai Nghiem. Workshop code available at trancethehuman/ai-workshop-code.