Claude Managed Agents: Anthropic's New API for Production AI Agent Deployment
Anthropic's Claude Managed Agents API lets developers define agents with tools, sandboxed environments, and success criteria. Claude works autonomously in isolated containers until the job passes your rubric.
Claude Managed Agents is Anthropic's new suite of APIs for building production-ready AI agents. Developers define tools, sandboxed environments, and measurable success criteria. Claude then works inside isolated containers with bash, file system access, and web search until the job meets the rubric. It's currently in limited research preview.
Video Summary
Anthropic released a 4-minute product demo showing Claude Managed Agents, a hosted API for deploying AI agents that run inside isolated containers with full tooling access. The demo walks through three real scenarios: a website performance optimizer that self-corrects against a Lighthouse rubric, a SaaS pricing auditor that uses memory to track week-over-week changes, and a multi-agent incident response system where a coordinator delegates to three specialists on a shared file system. The most striking detail: agents grade their own output against developer-defined criteria and iterate until they pass. Managed Agents is available as a limited research preview through an application form.
Key Insights
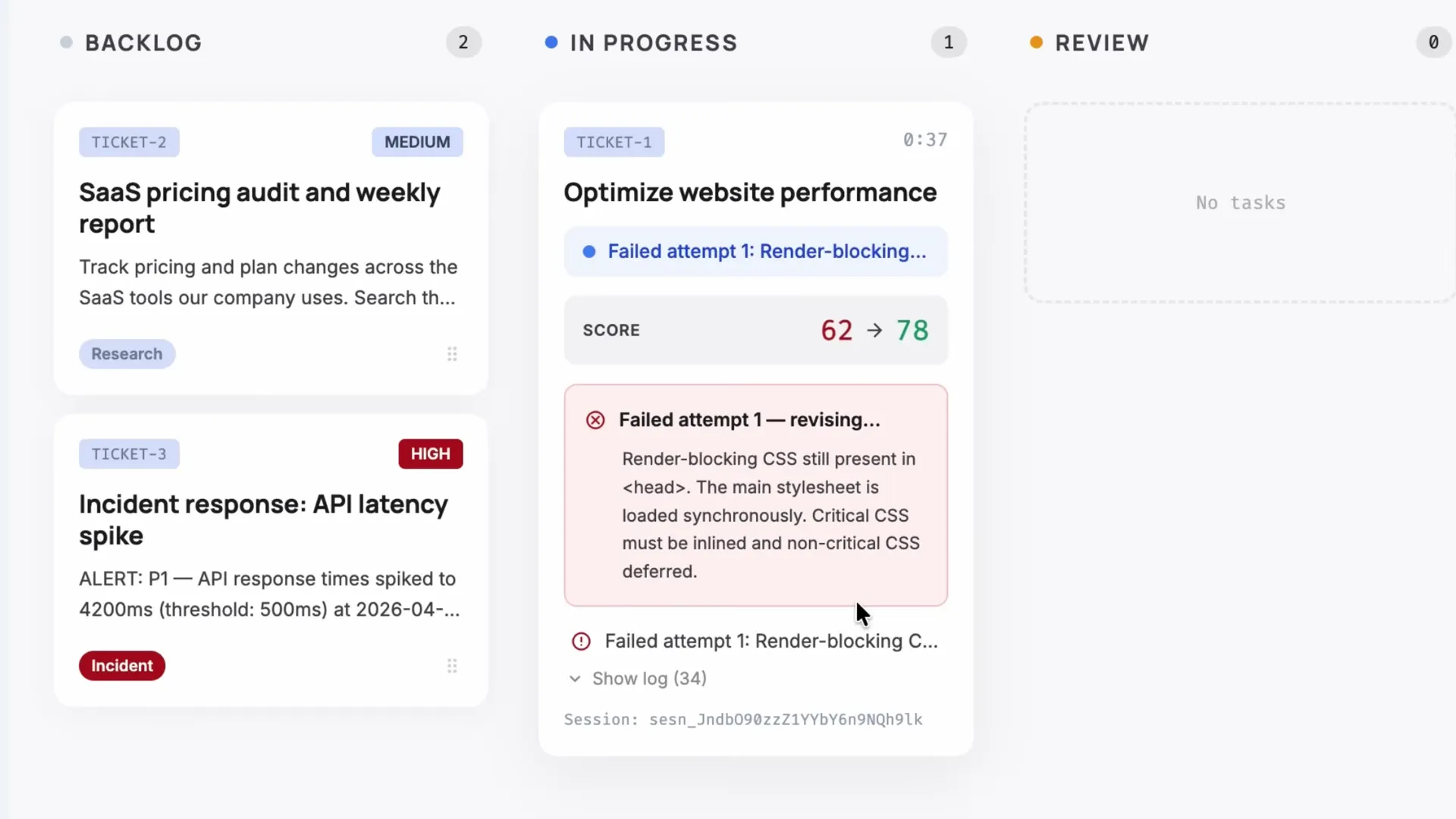
- Outcomes turn agents from "best effort" into "meet this bar." A separate grader running in its own context window evaluates the agent's output against developer-defined criteria. In the demo, the Lighthouse score rubric required 90+, no render-blocking resources, and all images lazy loaded. The agent failed its first attempt (score 62→78), read the grader's feedback, fixed what it missed, and hit 96.
Claude has the code base, the tools, and a rubric. Lighthouse score above 90. No render-blocking resources. All images lazy loaded.
-
Memory makes agents stateful across sessions. The SaaS pricing agent reads what it found last week before starting, then stores what changed after finishing. The next week's report says "cloud compute 15% lower since last week" instead of repeating static pricing data. This is the difference between a script and an assistant that improves over time.
-
Multi-agent coordination splits complex problems across specialist contexts. The incident response demo shows a coordinator agent delegating to three specialists (diagnostics, log analysis, communications), each with their own context window but sharing a file system. The coordinator synthesizes their findings into a single summary.
-
MCP servers connect agents to external services. The demo showed Slack and Asana connected via MCP (Model Context Protocol) servers. The pricing agent posts reports to Slack and creates review tasks in Asana without custom API integrations. This is MCP doing exactly what it was designed for.
-
Parallel sessions run independent tasks simultaneously. Two tickets can be dragged to "In Progress" at the same time. Each gets its own session, container, and isolated execution. No shared state between them.
I can drag a second ticket over while the first is still running. Two sessions, two containers, two separate tasks running in parallel.
-
Permission policies add human-in-the-loop gates. Before the incident response agent posted to Slack, a permission policy fired. The developer saw the draft on screen, approved it, and the message went out. You control which actions require approval.
-
Memory enables cross-incident pattern matching. The coordinator checked past incidents in the memory store and flagged a pattern: "This looks like the DNS resolution issue from two weeks ago caused by a misconfigured TTL." Next time a similar alert fires, the agent starts with that context instead of diagnosing from scratch.
I've been building agent pipelines at WebSearchAPI.ai for the past year. The part of this demo that made me stop and rewatch was the outcome grading loop. Most agent frameworks give you a "fire and hope" model: the agent runs, it does its best, you check the output. Managed Agents inverts that. You write the rubric, a separate grader enforces it, and the agent keeps going until it passes or exhausts its attempts.
That's a fundamentally different contract. It shifts the developer's job from "review every output" to "define what done looks like." If Anthropic can make that grading loop reliable at scale, it changes the economics of agent deployment.
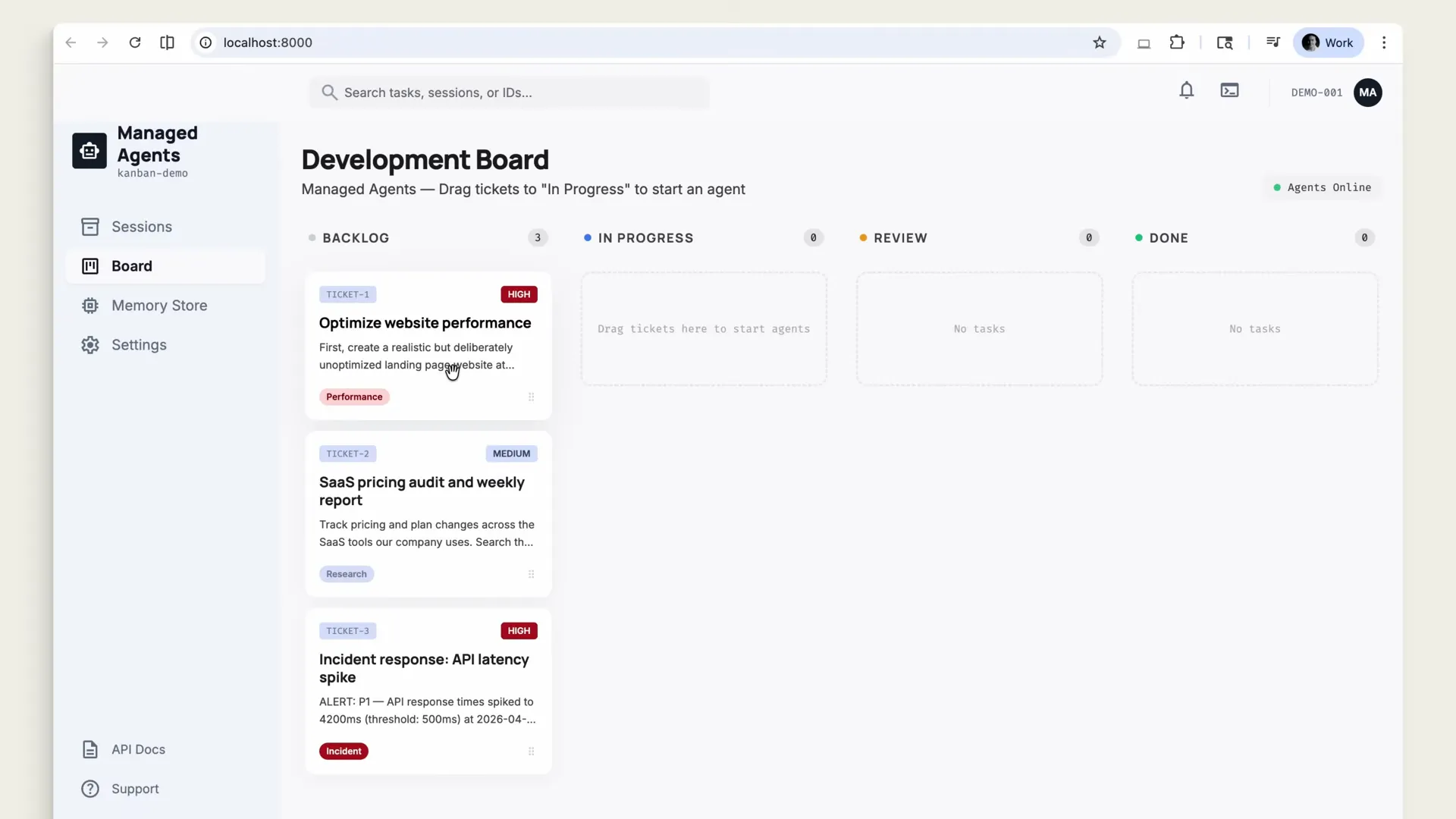
How Does the Outcome Grading System Work?
The demo showed the clearest example of self-correcting agent behavior I've seen from any provider. Here's the sequence:
- Developer defines an outcome rubric (Lighthouse 90+, no render-blocking CSS, all images lazy loaded)
- Claude runs inside a sandboxed container with Lighthouse and Puppeteer pre-installed
- The agent audits the site, starts compressing images, inlining CSS, deferring scripts
- A separate grader evaluates the result against the rubric
- Grader returns feedback: "Render-blocking CSS still present in head. Critical CSS must be inlined and non-critical CSS deferred"
- Claude reads the feedback, goes back in, fixes the issues, resubmits
- Score reaches 96. Rubric passes.
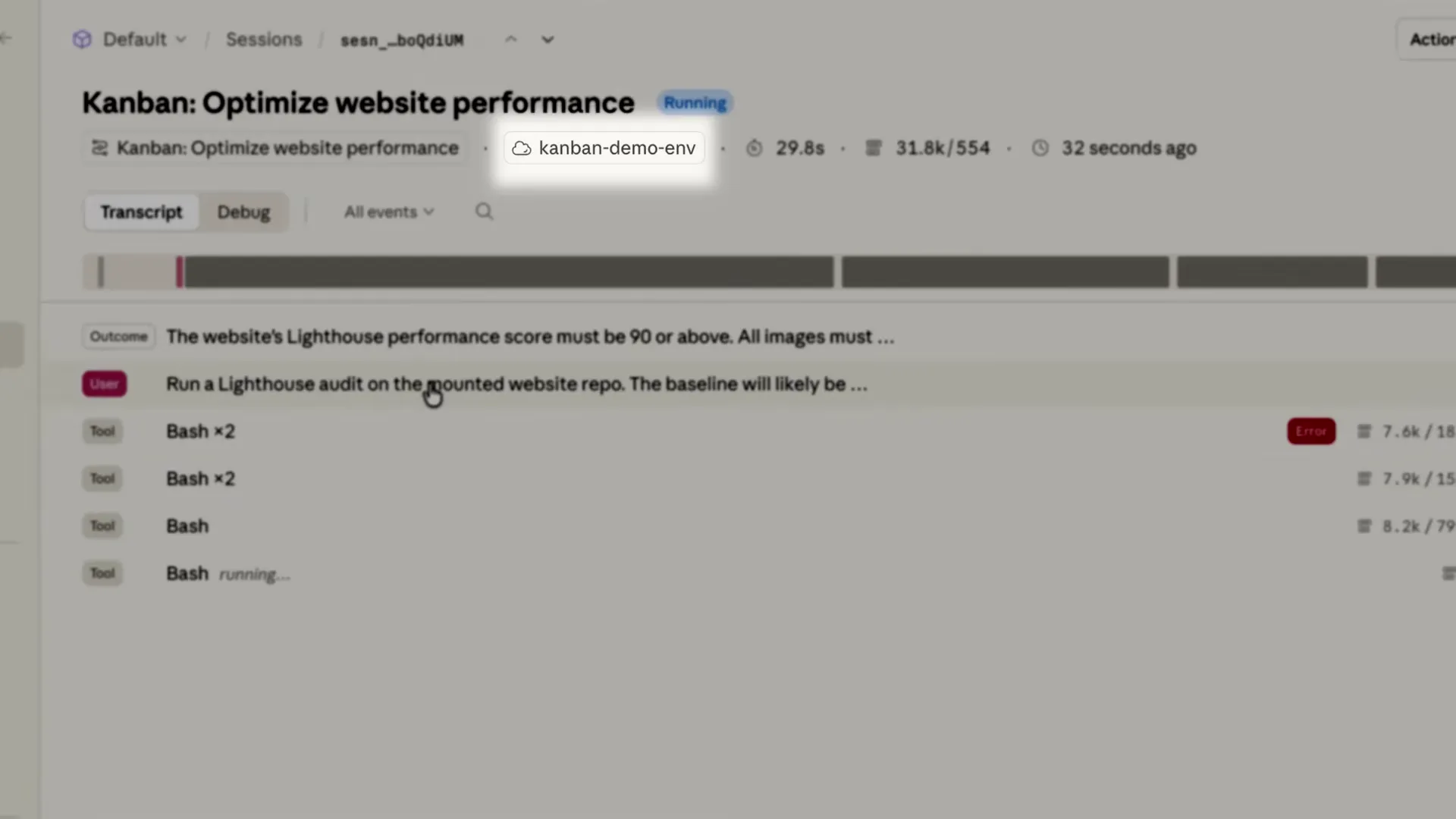
The grader runs in its own context window, separate from the agent. That separation matters. The agent can't rationalize away a failed criterion because it doesn't control the grading. It's the same principle behind separating test-writing from code-writing in software engineering.
The rubric kicks in, a separate grader running at its own context window evaluates the output against my criteria. Claude reads that feedback, goes back in, fixes what it misses, and resubmits.
I ran a quick comparison of how outcome-based grading compares to the approach other agent platforms take:
| Feature | Claude Managed Agents | OpenAI Agents SDK | LangGraph | AutoGen |
|---|---|---|---|---|
| Self-grading loop | Built-in with separate grader context | Manual implementation | Custom evaluator nodes | No built-in |
| Sandboxed execution | Isolated containers per session | Code interpreter sandbox | None (runs locally) | Docker optional |
| MCP support | Native (Slack, Asana shown) | No | LangChain tools | Tool plugins |
| Multi-agent coordination | Shared filesystem, separate contexts | Handoff-based | Graph-based | Conversation-based |
| Persistent memory | Built-in memory store | Thread-based context | Checkpointer | Stateful agents |
| Parallel sessions | Yes, isolated | Yes | Yes | Yes |
What Does the Memory System Actually Do?
The SaaS pricing audit demo showed the most practical use of agent memory I've seen. The agent doesn't just store data. It stores what changed.
Before it starts, it checks what it found last week. After it finishes, it stores what's changed. So next Monday's report says cloud compute 15% lower since last week instead of listing the same static pricing data.
The agent in this demo does five things in sequence:
- Searches the web for current pricing pages across the company's SaaS tools
- Detects changes by comparing against memory from last week's run
- Runs a cost analysis in Python inside the sandbox
- Writes an executive summary using an Excel spreadsheet skill
- Posts to Slack and creates a review task in Asana via MCP servers
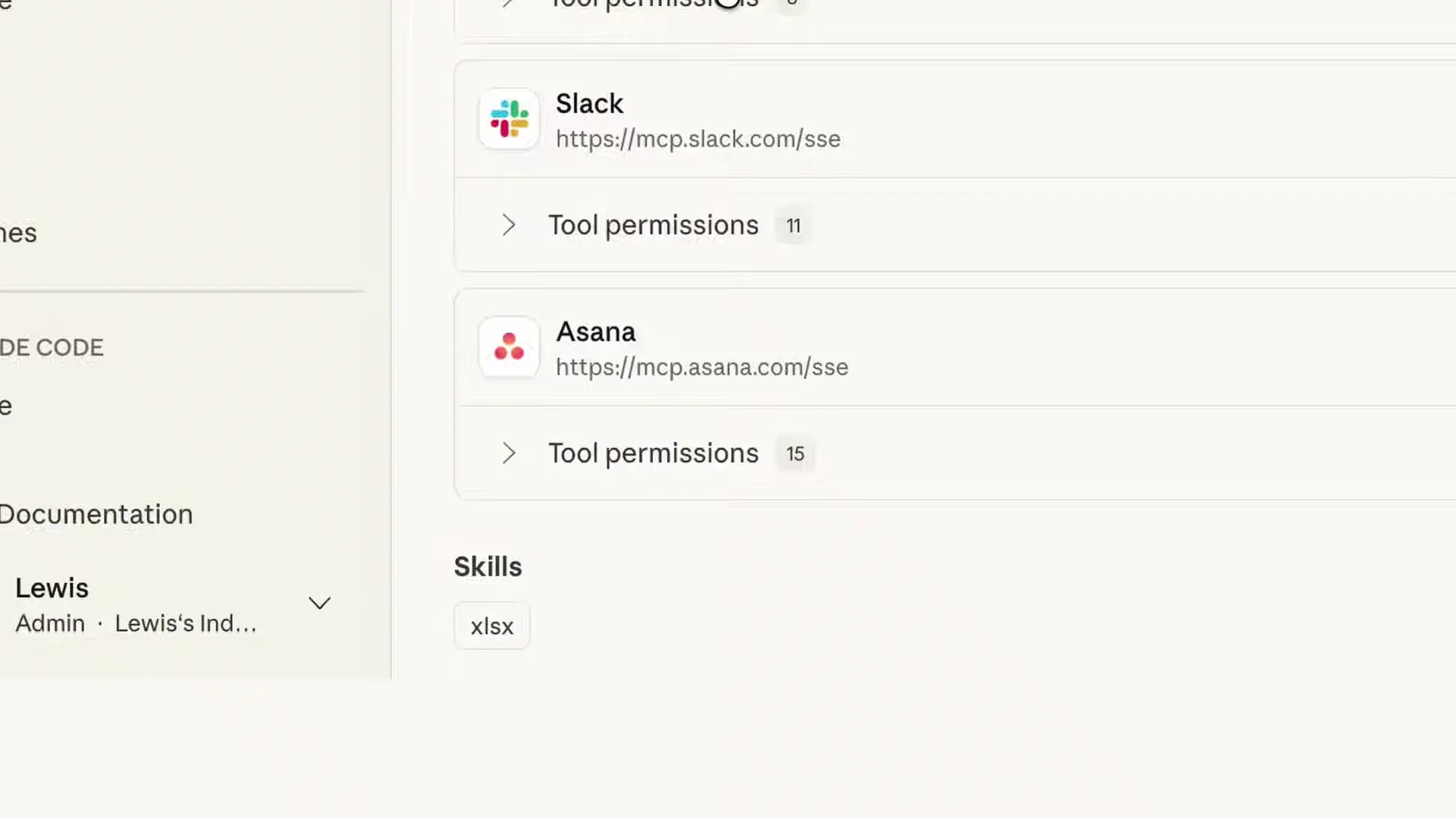
That last step is worth pausing on. The MCP integrations shown (Slack at mcp.slack.com/sse, Asana at mcp.asana.com/sse) suggest these are hosted MCP endpoints maintained by the service providers themselves. If that's the direction MCP is headed, where SaaS companies host their own MCP servers, it removes the biggest friction point in agent-to-service connectivity. No more wrangling OAuth flows and REST APIs per integration.
How Does Multi-Agent Incident Response Work?
This was the most complex demo. An alert fires from a monitoring stack. A custom tool on the backend receives the payload and creates a new Managed Agents session. But this session uses multi-agent coordination.
The coordinator agent receives the alert and delegates to three specialists:
- Diagnostics — Checks service health, memory, CPU, response times
- Log Analysis — Correlates timestamps, identifies root cause (DNS TTL set to 30s causing resolver floods)
- Communications — Writes incident summary, posts to Slack's #engineering channel
Each specialist runs in its own context window on the same shared file system. The coordinator synthesizes their findings.
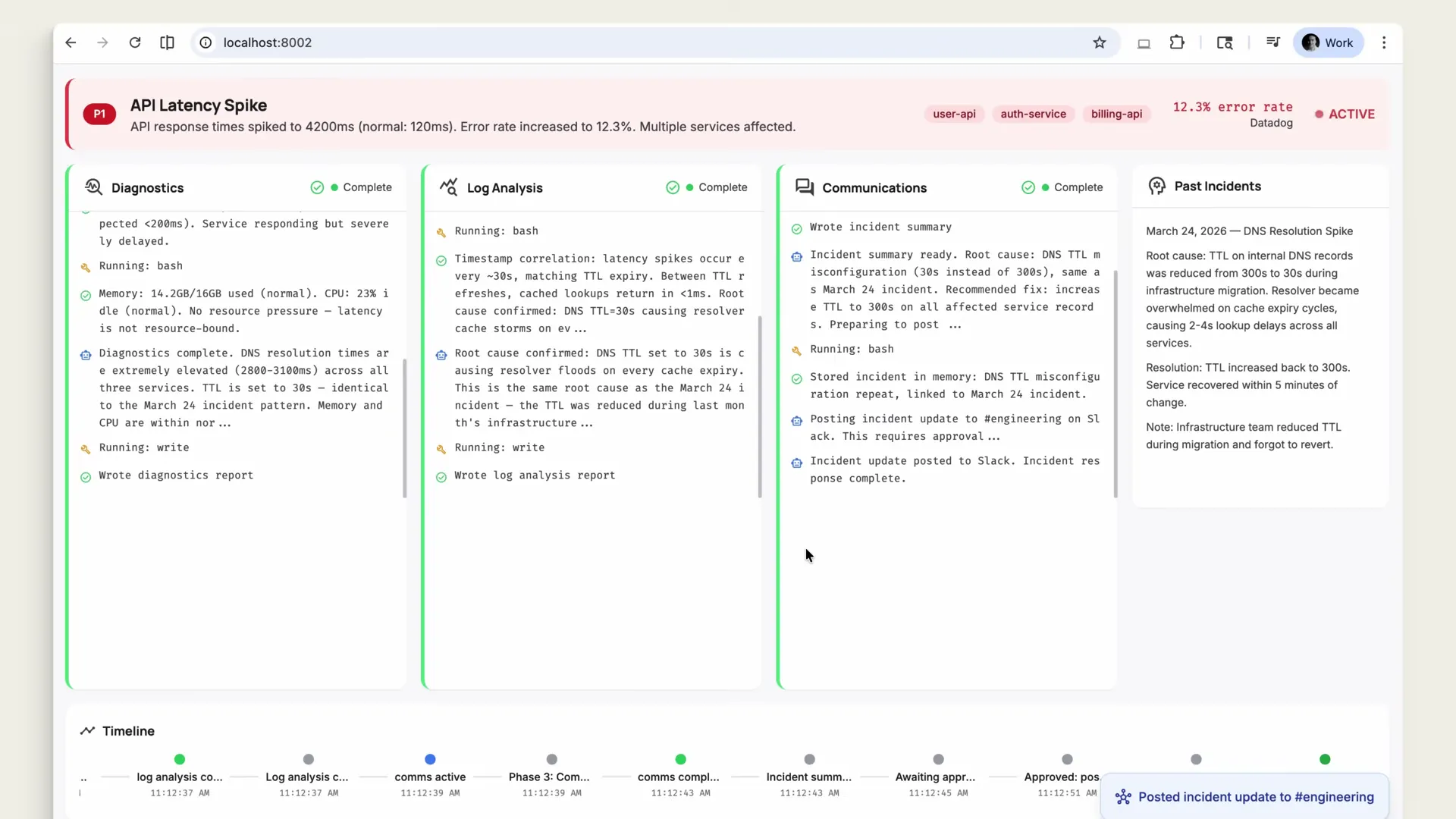
Two things stood out here. First, the permission policy. Before the Communications specialist posted to Slack, the system paused for human approval. The developer saw the draft, approved it, and the message went out. That's a critical safety pattern for any agent that writes to external services.
Second, the memory-based pattern matching. The coordinator checked past incidents and flagged: "This looks like the DNS resolution issue from two weeks ago that was caused by a misconfigured TTL." That context carries forward. Next time a similar alert fires, the agent starts from the known pattern instead of running diagnostics blind.
The coordinator checks past incidents in the memory store and flags a pattern. This looks like the DNS resolution issue from two weeks ago that was caused by a misconfigured TTL. The next time a similar alert fires, the agent starts with that context instead of diagnosing from scratch.
What Are the Seven Building Blocks of Managed Agents?
The demo closed with a clear architecture slide. Claude Managed Agents has seven components:
| Component | What It Does |
|---|---|
| Agents | Define persona, instructions, and capabilities |
| Sessions | Individual execution runs inside isolated containers |
| Environments | Pre-configured sandboxes with packages and network controls |
| Tools | Bash, file system, web search, custom tools |
| MCP | Connect to external services (Slack, Asana, etc.) via Model Context Protocol |
| Memory | Persistent store that carries context across sessions |
| Outcomes | Rubric-based grading with a separate evaluator context |
| Multi-Agent Coordination | Coordinator + specialists with shared filesystem |

That's eight items in the list, not seven. The video said seven but showed eight in the closing graphic. The distinction between "outcomes" and "multi-agent coordination" as separate primitives makes sense architecturally. They solve different problems: outcomes handle quality assurance for a single agent, coordination handles task distribution across multiple agents.
Frequently Asked Questions
What is Claude Managed Agents?
Claude Managed Agents is Anthropic's API suite for building and deploying production AI agents. Developers define agents with specific tools, sandboxed environments, and success criteria. Claude then works autonomously inside isolated containers with bash execution, file system access, and web search until the task meets the defined rubric.
How do I get access to Claude Managed Agents?
Claude Managed Agents is currently in limited research preview. Outcomes, multi-agent orchestration, and memory are available through an early access application at claude.com/form/claude-managed-agents. Anthropic hasn't announced general availability pricing or timeline.
How does the outcome grading system work?
A separate grader runs in its own context window and evaluates the agent's output against developer-defined criteria. In Anthropic's demo, the Lighthouse performance rubric required a score above 90, no render-blocking resources, and all images lazy loaded. The agent iterated from a score of 62 through 78 to 96, fixing issues identified by the grader at each step.
Can Claude Managed Agents connect to external services like Slack and Asana?
Yes. The demo showed agents posting to Slack and creating tasks in Asana through MCP (Model Context Protocol) servers. The settings UI displayed hosted MCP endpoints at mcp.slack.com/sse and mcp.asana.com/sse, each with configurable tool permissions.
How does memory work across agent sessions?
Agents read from and write to a persistent memory store. Before starting a task, the agent checks what it found in previous sessions. After finishing, it stores what changed. According to the demo, this allows week-over-week comparisons: "cloud compute 15% lower since last week" rather than repeating static data every run.
What is multi-agent coordination in Managed Agents?
Multi-agent coordination lets a coordinator agent delegate tasks to specialist agents. Each specialist runs in its own context window but shares a file system with the others. In the incident response demo, a coordinator delegated to diagnostics, log analysis, and communications specialists, then synthesized their findings into a single incident summary.
How does Claude Managed Agents compare to OpenAI's Agents SDK?
Claude Managed Agents provides built-in outcome grading, persistent memory, and native MCP support. OpenAI's Agents SDK uses a handoff-based approach for multi-agent workflows and relies on thread-based context rather than persistent memory. The biggest difference is the outcome loop: Managed Agents enforces pass/fail criteria with a separate grader, while OpenAI's SDK requires manual implementation of evaluation logic.
Can multiple agent sessions run in parallel?
Yes. Each session gets its own isolated container. The demo showed two tickets running simultaneously, each with independent execution and no shared state. This enables batch processing of tasks where results don't depend on each other.
Key Takeaways
- Outcome-based grading is the standout feature. A separate grader context evaluates agent output against your rubric and sends the agent back to fix what it missed. This moves agents from "best effort" to "meet this bar."
- Memory carries context across sessions, enabling week-over-week comparisons and cross-incident pattern matching instead of starting from scratch every time.
- Multi-agent coordination splits problems across specialist contexts that share a file system, with a coordinator synthesizing findings.
- MCP integration with Slack and Asana suggests a model where SaaS providers host their own MCP endpoints, removing per-service API integration work.
- Permission policies gate external actions, requiring human approval before agents post to Slack or other public channels.
- Managed Agents is in limited research preview. Apply at claude.com/form/claude-managed-agents. No public pricing or GA date has been announced.
This post is based on What is Claude Managed Agents? by Claude.