How Transformers Work: Attention Is All You Need, Explained Step by Step
ByteByteGo's 10-minute transformer explainer, annotated by a production AI engineer. Self-attention, Q/K/V vectors, matrix form math, and what changed since 2017 — from FlashAttention 4 to DeepSeek's MLA.
ByteByteGo's 10-minute explainer unpacks the transformer architecture from the 2017 paper Attention Is All You Need — cited over 173,000 times and still the foundation of every frontier LLM. This deep dive annotates the video with production insights from running transformer-based retrieval at WebSearchAPI.ai, adds the math and modern variants ByteByteGo skipped, and covers what actually changed between 2017 and 2026.
A transformer is a deep neural network that lets every input token attend to every other token in parallel, using learned query, key, and value projections to decide which relationships matter. It replaced recurrent networks in 2017, powers GPT-4, Claude 3.7, Gemini 2, and LLaMA 3, and remains the default architecture even as hybrid SSM/attention models like Mamba and DeepSeek's MLA push its efficiency frontier.
Video Summary
ByteByteGo — the engineering education channel run by system-design author Alex Xu — walks through the transformer architecture in under 10 minutes. The video starts from neural network basics, then explains why sequential models like RNNs and LSTMs struggled with long-range context. From there it unpacks the attention mechanism using a running example ("Jake learned AI even though it was difficult"), shows how each token becomes a query, key, and value vector, and demonstrates how matrix-form computation makes training parallelizable. The single most important takeaway: a transformer is a network that lets its inputs talk to each other, and that simple idea is the reason Vaswani et al.'s 2017 paper now underpins every frontier LLM from GPT-4 to Claude to Gemini. The ByteByteGo channel regularly produces this kind of visual system-design teardown — if you liked this one, their companion explainer on how search engines really work covers the other side of the AI stack.
Transformer Key Insights
- Transformers solved two RNN problems at once: parallelism and long-range context. RNNs processed tokens one at a time, which made training slow and caused early information to decay by the end of long sequences. Attention replaces that sequential loop with a single parallel operation where every token sees every other token directly. According to a widely cited LinkedIn post from researcher Sachin K.G., "The genius of the Transformer is that it treats the whole sentence as a single matrix operation. That shift from O(N) to O(1) for sequential operations is exactly why we can saturate massive GPU clusters."
Transformers, introduced in the 2017 paper Attention Is All You Need published by Google, solved both issues. The transformer is still a neural network, a sequence of layers, but its design is smarter. It adds a special layer called attention, which lets all tokens in a sequence talk to each other directly.
-
Attention is just a communication layer. Every token "looks at" all other tokens and decides which ones are relevant. ByteByteGo's framing — tokens talking to each other — is the cleanest way to teach attention without jumping straight into the math. It's also the mental model I use when debugging retrieval quality in production RAG systems at WebSearchAPI.ai: when an LLM ignores a relevant chunk, the first thing I check is whether that chunk ended up with attention weight too low to matter.
-
Query, Key, Value is a library search metaphor, not mysticism. Each token projects itself three ways: a query ("what am I looking for?"), a key ("here's what I have"), and a value ("here's the content I'll share"). Relevance is the dot product of one token's query against every other token's key.
The query asks, what am I looking for? The key contains, here is what I have, and the value carries the actual content to share.
-
The entire attention layer is one matrix multiplication. Instead of looping over tokens, the paper expresses Q, K, and V as matrices and computes all interactions simultaneously. This is the single reason transformers scale so well on GPUs. The current state of the art is Flash Attention 4, hitting 1,605 TFLOPs/s on NVIDIA Blackwell GPUs as of March 2026 — a number that would have been science fiction when the original paper was published.
-
Training starts from random noise and bootstraps meaning. At step zero, the Q/K/V projection weights are garbage. Over millions of training steps, the model learns that pronouns should look at nouns, verbs should look at their subjects, and closing brackets should look at opening ones. No one hand-codes these patterns — they emerge from gradient descent. This emergence is also why subtle training choices produce dramatically different downstream behavior, and why AI reward hacking becomes such a tricky problem once the attention patterns are baked in.
For instance, verbs like learned start querying their subjects, and pronouns like it learn to look toward relevant nouns like AI.
-
Transformers generalize far beyond text. The same architecture now handles images (Vision Transformers), audio (Whisper), protein folding (AlphaFold 2), and video. Google's own research team reports that transformer models often outperform specialized graph neural networks on graph reasoning tasks, which nobody predicted in 2017.
-
Encoder-decoder, encoder-only, and decoder-only are three flavors of the same architecture. The original 2017 paper used encoder-decoder for translation. BERT is encoder-only (good for classification and embeddings). GPT is decoder-only (good for generation). All three are the same attention mechanism wired differently — including modern systems like Gemini 3 and Claude's Web Search API.
-
The transformer era might not last forever. A provocative LinkedIn post from researcher Sid Ab argued that "Transformer will be dead by 2026" — predicting hybrid architectures where 70% of tokens are processed by state space model (SSM) "experts" and 30% are routed to attention for deeper analysis. We're not there yet. But the fact that serious researchers are talking this way is a signal the monoculture is starting to crack, and it matters for anyone building production RAG: a new architecture could shift the whole web search API and retrieval stack.
I've spent most of the past few years at WebSearchAPI.ai designing infrastructure that feeds live web data into transformer-based LLMs and AI agents. One of the unsexy realities of that work: I think about attention far more for its cost than its elegance. Every query our customers send through the WebSearchAPI retrieval engine eventually hits a transformer somewhere downstream, and every extra token in the context window means more quadratic attention cost, more GPU-seconds billed, and more latency before the user sees a response. When we cut hallucination rates by 45% through better ranking pipelines, a huge chunk of that win came from making sure only the right tokens ever entered the attention layer in the first place.
That's the angle I want to bring to ByteByteGo's video. The 10-minute explainer is a near-perfect conceptual introduction — I'd hand it to any engineer joining the team who hadn't seen the architecture yet. But it's 10 minutes, which means it had to cut things that matter in production: the O(n²) memory wall, positional encoding variants, FlashAttention, mixture-of-experts, and the hidden GPU economics that determine which architecture choices actually ship. I'll quote ByteByteGo for the core explanation, then fill in what the video skipped. If you're building with LLMs and want the mental model first, watch the video and read the Key Insights above. If you want to understand why a 2017 paper is still the bottom of the stack for GPT-4, Claude, Gemini, and LLaMA — keep reading.
What Problem Were Transformers Actually Built to Solve?
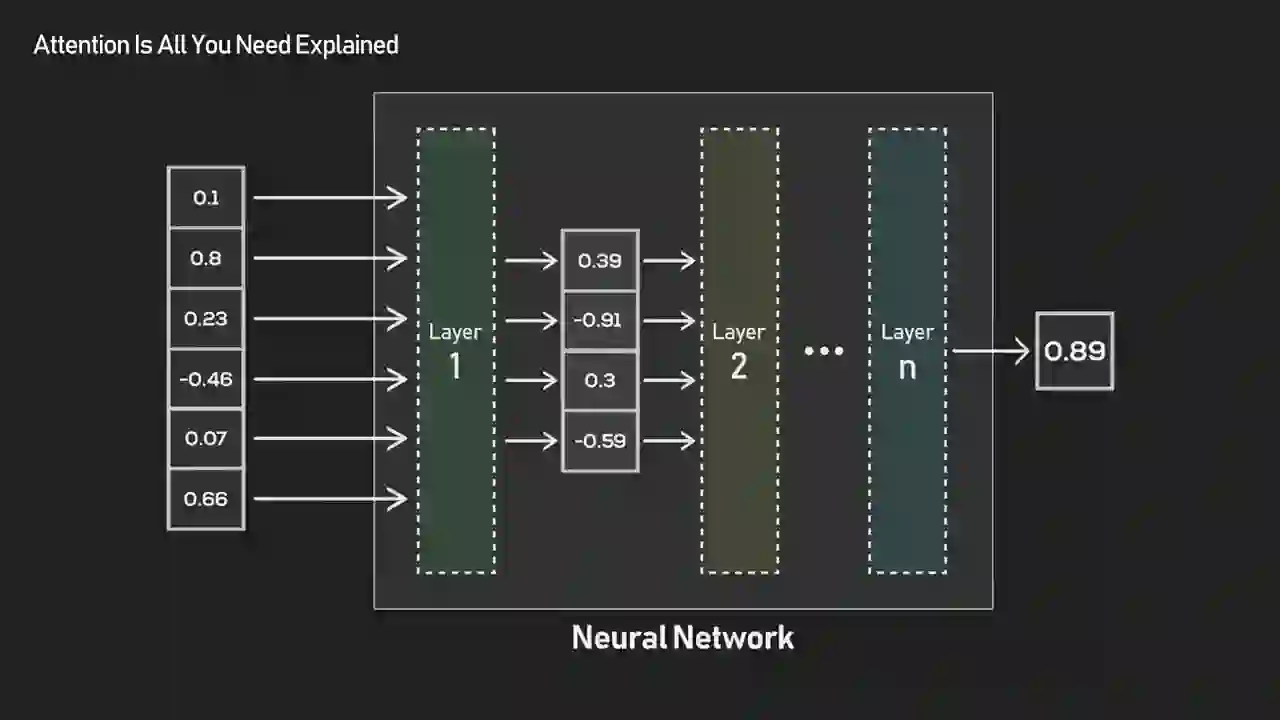
Transformers were built to handle sequential data — sentences, code, audio, anything ordered — without the two crippling limitations of the models that came before them. ByteByteGo opens with the core framing of machine learning: every model is a function that maps inputs to outputs. The interesting question is how you design that function when the input is a sequence and the meaning of each token depends on everything around it.
For sequential tasks such as sentiment analysis, things get tricky. If each token in a sequence, say each word in a sentence, is processed and transformed independently, the model loses all sense of context.
The toy example of sentiment analysis hides the real difficulty. Take the sentence "The movie wasn't as bad as I feared." A model that scores each word independently sees "bad" and "feared" and grades it negative. A model that reads the sequence as a whole sees the hedging structure and grades it mildly positive. Context isn't decoration — it's the entire task.
I hit a harder version of the same problem on my first production RAG system at WebSearchAPI.ai. We were pulling 50-100 search results per query, stitching them into a context window, and feeding the whole thing to an LLM. The early version occasionally answered questions using content from the middle of the context that contradicted content from the start, because early tokens were decaying in importance by the time attention heads were processing later chunks. Transformers solve this in theory — every token can see every other token — but in practice, long contexts still have subtle attention dilution problems, which is why modern long-context models use techniques like landmark attention and grouped-query attention on top of vanilla self-attention.
Before transformers, the standard answer to sequence modeling was recurrence: process tokens in order, carry state forward, hope the state still remembers what mattered at the beginning by the time you hit the end. That worked, roughly, for short sequences. It collapsed on long ones.
Why Did RNNs and LSTMs Fall Short?
RNNs and LSTMs failed for two reasons: they were sequential (no parallelism) and they struggled with long-range dependencies (early information decayed). Both problems compound as sequences get longer, which is exactly the regime modern AI wants to operate in.
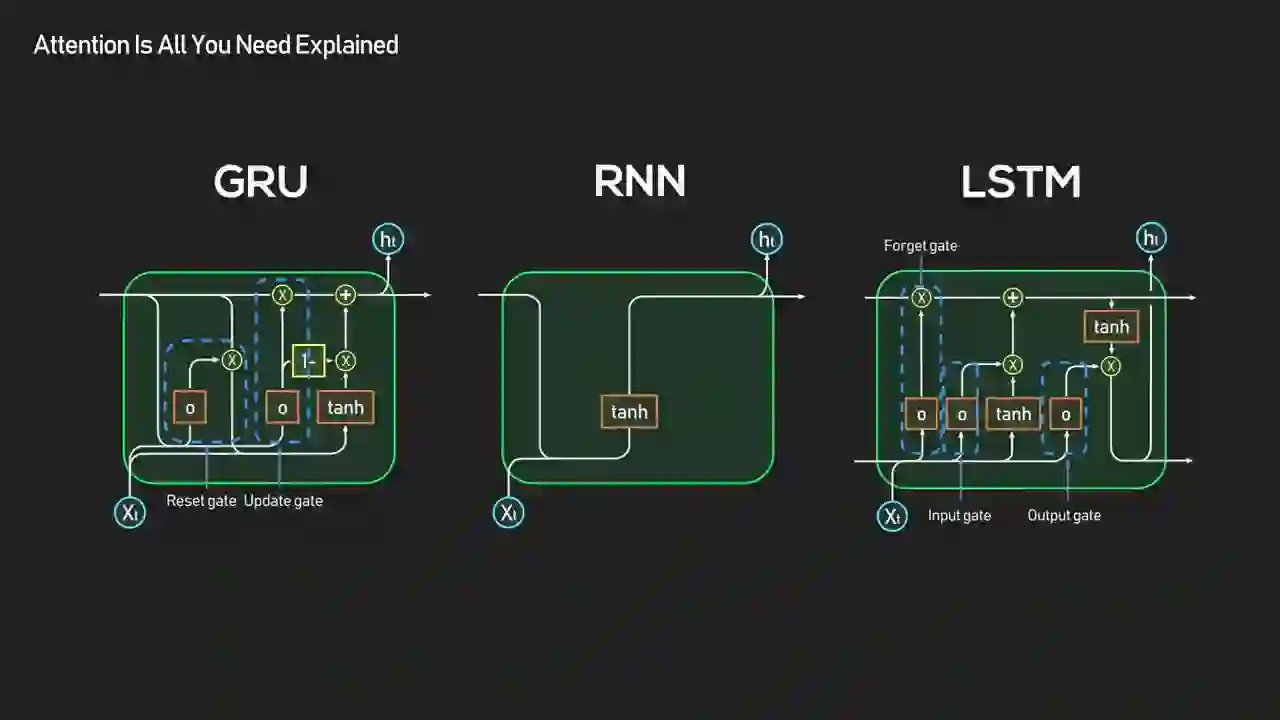
It worked, but it came with two big problems. First, it was sequential. No parallel processing, which made training slow. Second, it struggled with long-term dependencies. By the time the network reached the end of a long sequence, much of the early information was lost.
Both limitations are structural, not fixable by tweaks. The sequential constraint comes from the definition of recurrence itself — step t literally cannot start until step t-1 finishes. That's fine on a CPU, disastrous on a GPU with thousands of cores sitting idle. The long-range problem comes from the way gradients flow backward through time: by the time the error signal reaches step 1 from step 500, it's been multiplied by hundreds of matrices and typically either vanishes to zero or explodes to infinity. LSTMs and GRUs helped with the vanishing gradient problem through gating, but they never fixed the sequential bottleneck.
Numbers tell the story. The original "Attention Is All You Need" paper reported that their model "achieves 28.4 BLEU on the WMT 2014 English-to-German translation task" — beating the best RNN-based systems while requiring "significantly less time to train" because of the parallelism. Training a large RNN on a long-sequence corpus was a multi-week affair even in 2016. The frustration that would eventually produce transformers was, in part, a hardware frustration: the fastest chips on Earth were waiting on for loops.
| Capability | RNN / LSTM | Transformer |
|---|---|---|
| Training parallelism | No — sequential by design | Yes — full parallel matrix ops |
| Long-range context | Decays exponentially | Constant (one attention hop) |
| GPU utilization | 10-30% of peak FLOPs | 40-60%+ on modern hardware |
| Memory complexity | O(n) | O(n²) in sequence length |
| Inference speed (short seq) | Fast per token | Comparable per token |
| Inference speed (long seq) | Slow (sequential) | Slow (quadratic) |
| 2024 production usage in LLMs | Near-zero | Essentially 100% |
The O(n²) memory complexity listed in that table is the one limitation transformers still struggle with — I'll come back to it in the section on FlashAttention.
What Is Attention and Why Does It Change Everything?
Attention is a layer that lets every token in a sequence directly exchange information with every other token in a single parallel operation. It replaces "pass state forward one step at a time" with "let everyone read from everyone else simultaneously."
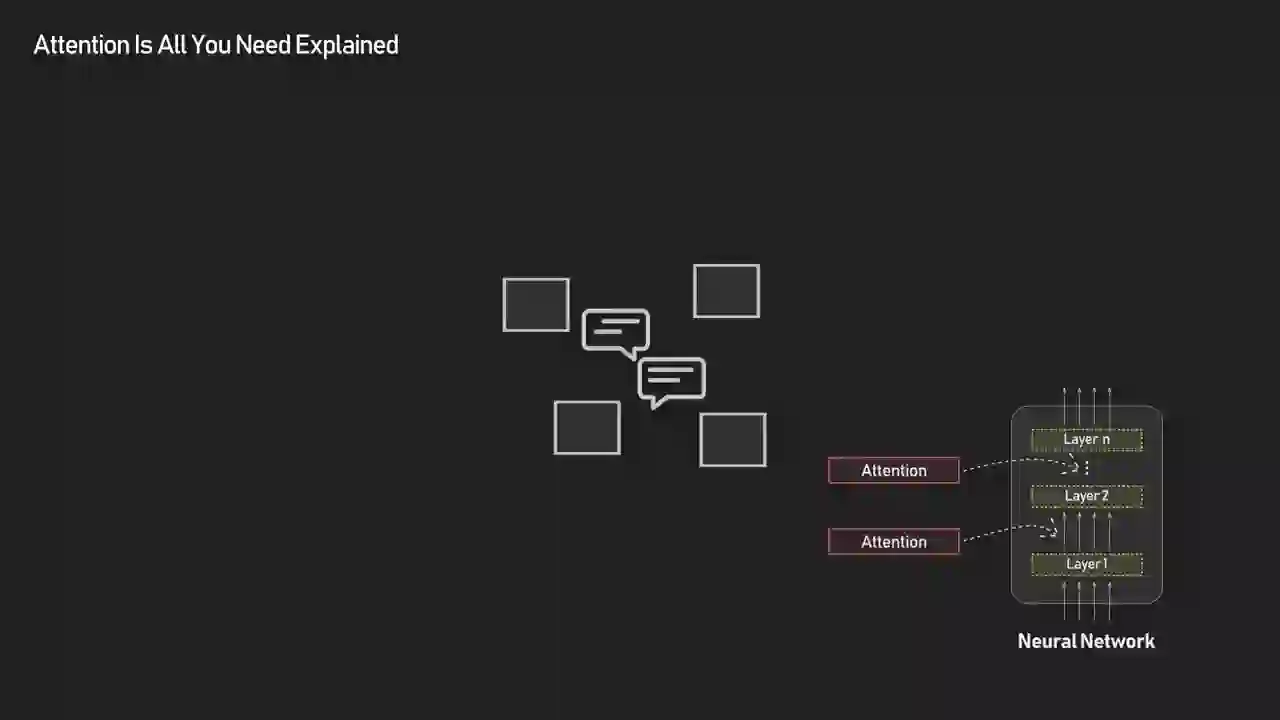
You can think of attention as a communication layer built inside the network. Each token looks at all others and decides which ones are important for better learning the mapping for the task at hand.
This framing does a lot of work. The thing that makes attention powerful isn't any single mathematical trick — it's the shape of the computation. In an RNN, information flows along a chain. In an attention layer, information flows across a fully connected graph where every token is one hop away from every other token. Whether two related words are 2 tokens apart or 2000, the path length is the same: one attention step.
There's also a property that often gets overlooked: attention is content-addressable. An RNN's hidden state is positional — you access information based on where you are in the sequence. Attention is associative — you access information based on what a token means. That distinction is why transformers generalize well to tasks like code completion, where the relevant "context" might be a function definition 500 lines earlier, or protein folding, where the relevant "context" is a residue on the opposite side of a 3D structure.
The cost of this flexibility is quadratic memory (every pair of tokens gets a score, so an n-token sequence needs n² slots), which is the limitation ByteByteGo didn't cover but that drives a lot of current research — FlashAttention, sliding window attention in Mistral, linear attention variants, and state space models like Mamba. None of them have dethroned vanilla self-attention yet, which tells you something about how strong the default is.
How Is the Transformer Architecture Actually Organized?
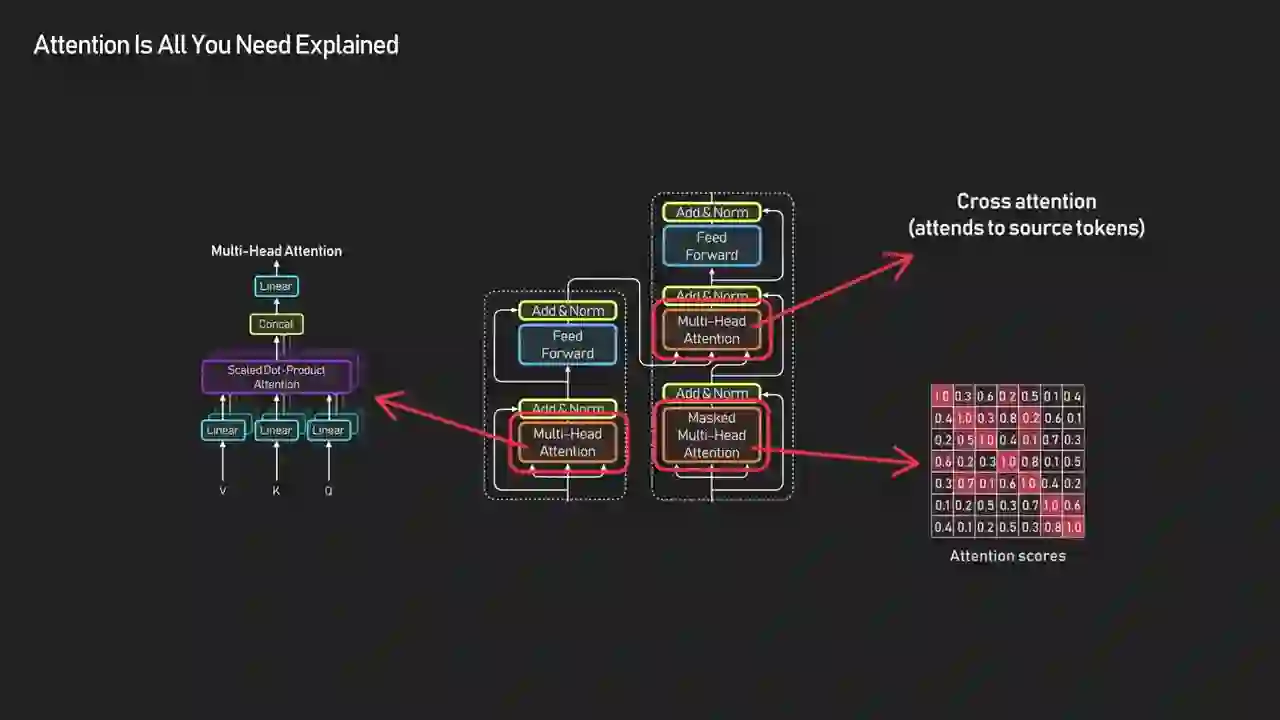
The transformer splits into an encoder and a decoder, both built from stacked blocks. Each block contains two layers: attention (where tokens exchange information) and a feed-forward MLP (where each token privately refines its own representation). Residual connections and layer normalization wrap around these to keep training stable.
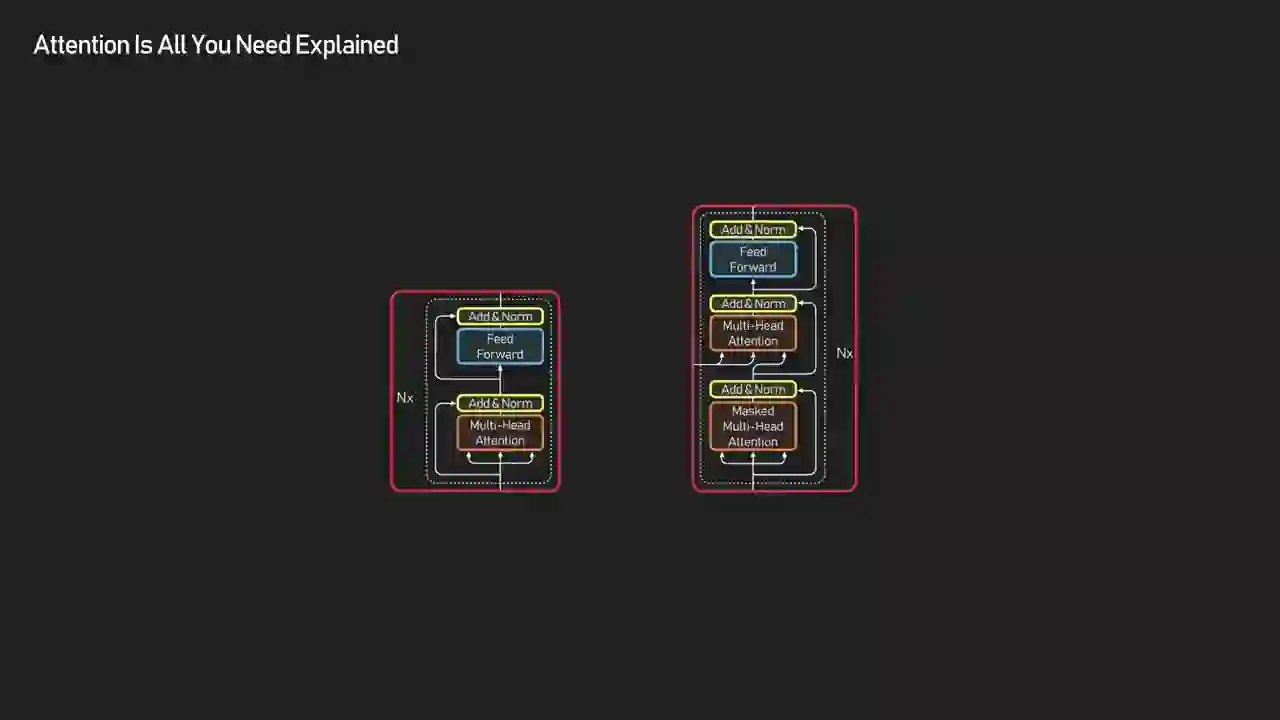
| Layer | What It Does | Communication Type |
|---|---|---|
| Self-Attention | Every token looks at every other token in the same sequence | Token-to-token (all pairs) |
| Feed-Forward (MLP) | Each token independently transforms its own vector | Token-private |
| Add & Norm | Adds residual connection + normalizes activations | Training stability |
| Cross-Attention (decoder only) | Decoder tokens look at encoder tokens | Sequence-to-sequence |
| Masked Self-Attention (decoder only) | Tokens can only attend to previous positions | Causal / autoregressive |
This combination of communication and attention and then individual refinement through the MLP layer is what helps the transformer build contextual understanding. Other details such as residual connections and layer normalization are there just to keep training stable.
Calling residual connections and layer norm "just" training stabilizers is fair for a 10-minute video, but it understates them. Without residuals, you can't train a transformer past a handful of layers — the gradients die. Without layer normalization, activations drift and training diverges. Every deep learning paper since 2017 that tries to replace these two operations (RMSNorm, pre-norm vs post-norm placement, ReZero, etc.) is a tweak to get a few percent of training efficiency back. The architecture is a tightly tuned system, not a stack of independent choices.
Here's the split most developers see in the wild. The original 2017 paper used the full encoder-decoder setup for translation. Then the ecosystem specialized:
- Encoder-only (BERT, RoBERTa, DeBERTa): great for classification, embeddings, and any task where you need a single dense representation of the whole input. Most semantic search and retrieval pipelines still use encoder-only models for embedding generation because they're faster per token than decoder-only.
- Decoder-only (GPT, Claude, LLaMA, Mistral, Gemini): great for generation. The causal mask means each token can only see past tokens, which is exactly what next-token prediction needs.
- Encoder-decoder (T5, BART, the original Transformer, Whisper): good for sequence-to-sequence tasks like translation and summarization where the input and output are distinct sequences.
Most frontier LLMs in 2026 are decoder-only. That includes GPT-4, Claude 3.7, Gemini 2, LLaMA 3, and Mistral Large. In our own production RAG stack at WebSearchAPI.ai, we use encoder-only models (like all-mpnet-base-v2 and newer BGE variants) for embedding the web content we index, and then decoder-only models for the final answer generation. The split matches the mental model: encoders understand, decoders generate, and most real systems need both.
How Do Inputs Flow Through a Transformer?
Inputs flow through four stages: tokenization (split text into tokens), embedding (convert tokens to vectors), positional encoding (add order information), and then repeated attention + MLP layers until you get a final context-aware representation. Different tasks tap into those final vectors differently.
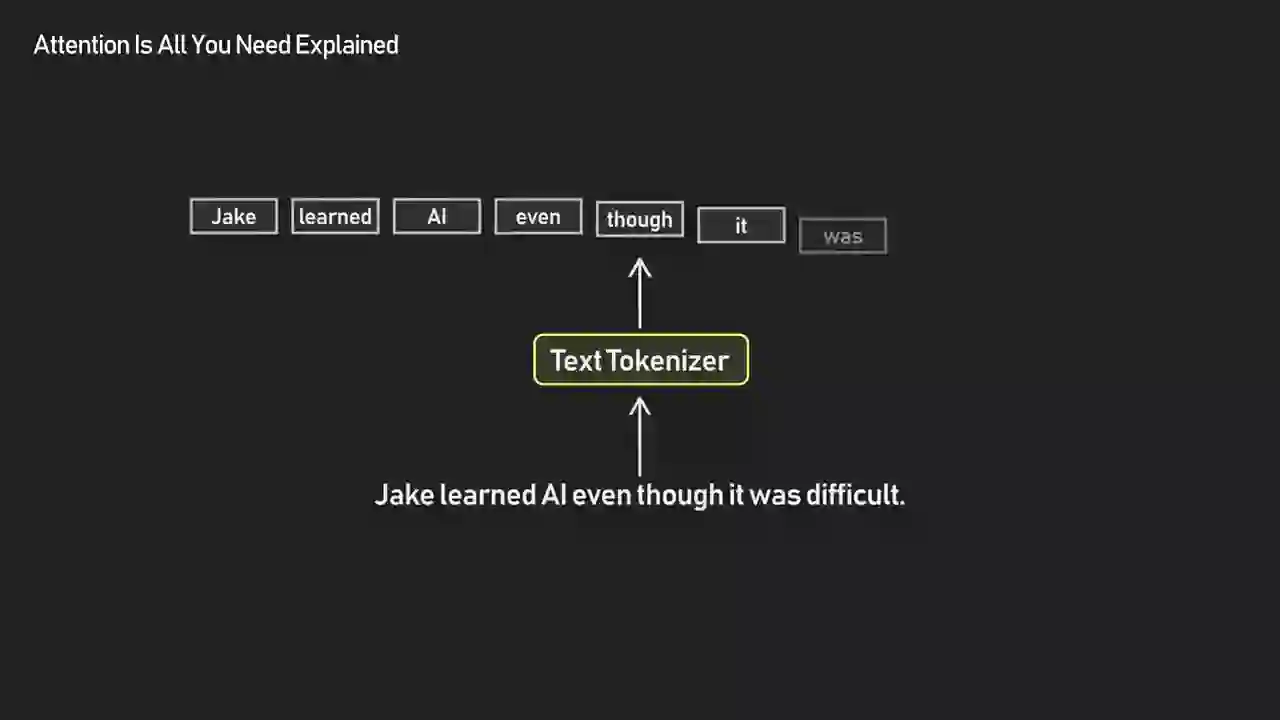
Transformer has no sense of order by default. So we add positional information to embeddings to introduce a sense of order among tokens. Without this, Jake learned AI could look the same as AI learned Jake.
The "no sense of order" point is the one most people miss on first read. Self-attention is a set operation — you could shuffle the token order and the attention weights would come out identical. That's a feature for parallelism and a bug for language. Positional encoding is the fix: you add a position-dependent vector to each token's embedding before the first attention layer, and suddenly order matters.
The original paper used fixed sinusoidal encodings. Modern models almost all use something different:
| Positional Encoding | Used In | Advantage | Limitation |
|---|---|---|---|
| Sinusoidal (fixed) | Original Transformer (2017) | No learned parameters, deterministic | Poor length extrapolation |
| Learned absolute | BERT, early GPTs | Simple, works well in training range | Can't extrapolate past training context length |
| RoPE (Rotary) | LLaMA, Mistral, GPT-NeoX, Qwen | Relative position, good extrapolation | Slightly more compute per layer |
| ALiBi | BLOOM, MPT | No position embeddings at all, extrapolates well | Slightly worse in-distribution performance |
| NoPE | Some recent research | Discovers position implicitly from causal mask | Only works in decoder-only |
If you've ever wondered why the context windows on frontier models jumped from 4K to 32K to 128K to 1M in the span of two years, a big part of that is better positional encoding schemes. The attention mechanism itself didn't change — the way we tell it about position did. Gemini 2's 2M-token context window, for instance, wouldn't work with vanilla sinusoidal encodings — you need RoPE or something equivalent to keep the positional signal coherent that far out.
What Are Query, Key, and Value Vectors?
Query, Key, and Value are three learned projections of each input token. The query asks "what am I looking for?", the key advertises "here's what I contain," and the value holds "here's the content I'll contribute if you pick me." Attention weights come from matching queries against keys; the output is a weighted sum of the values.
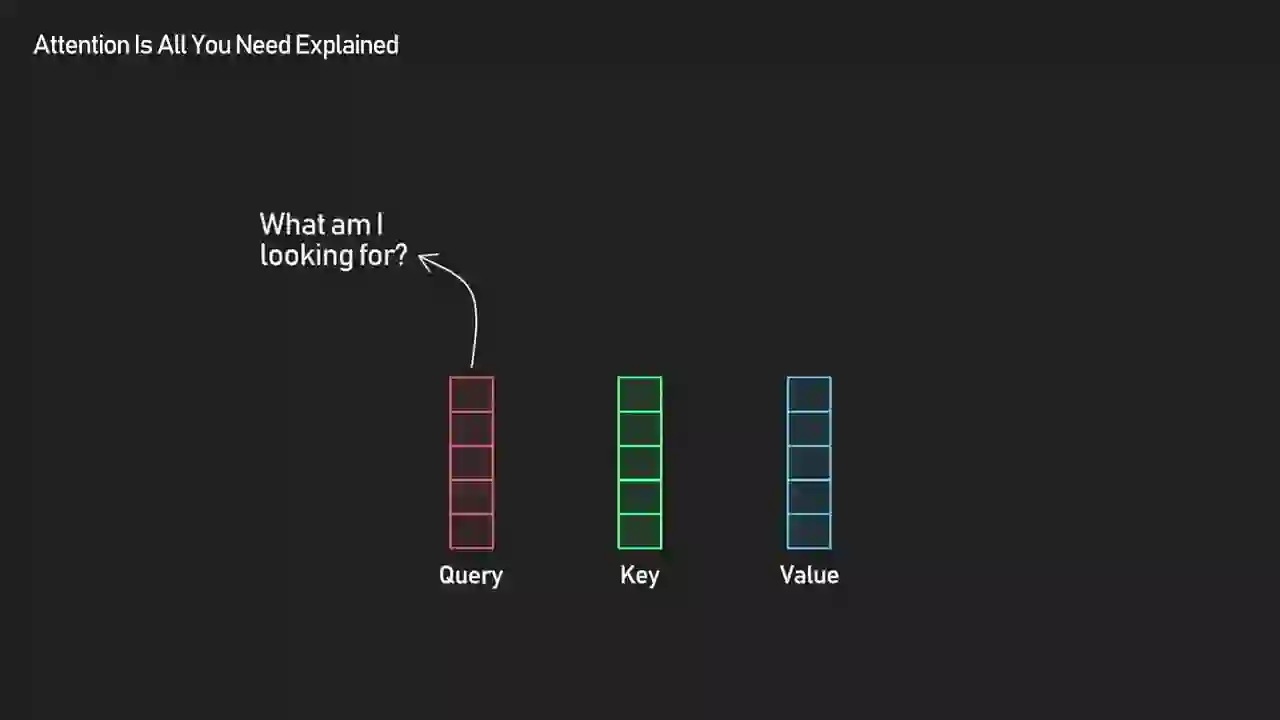
ByteByteGo's example is the cleanest one I've seen. Take the sentence "Jake learned AI even though it was difficult." The word "it" is ambiguous. What does a pronoun look for? Its antecedent. That's exactly what the query vector for "it" encodes after training — a pattern that matches well against noun-like keys.
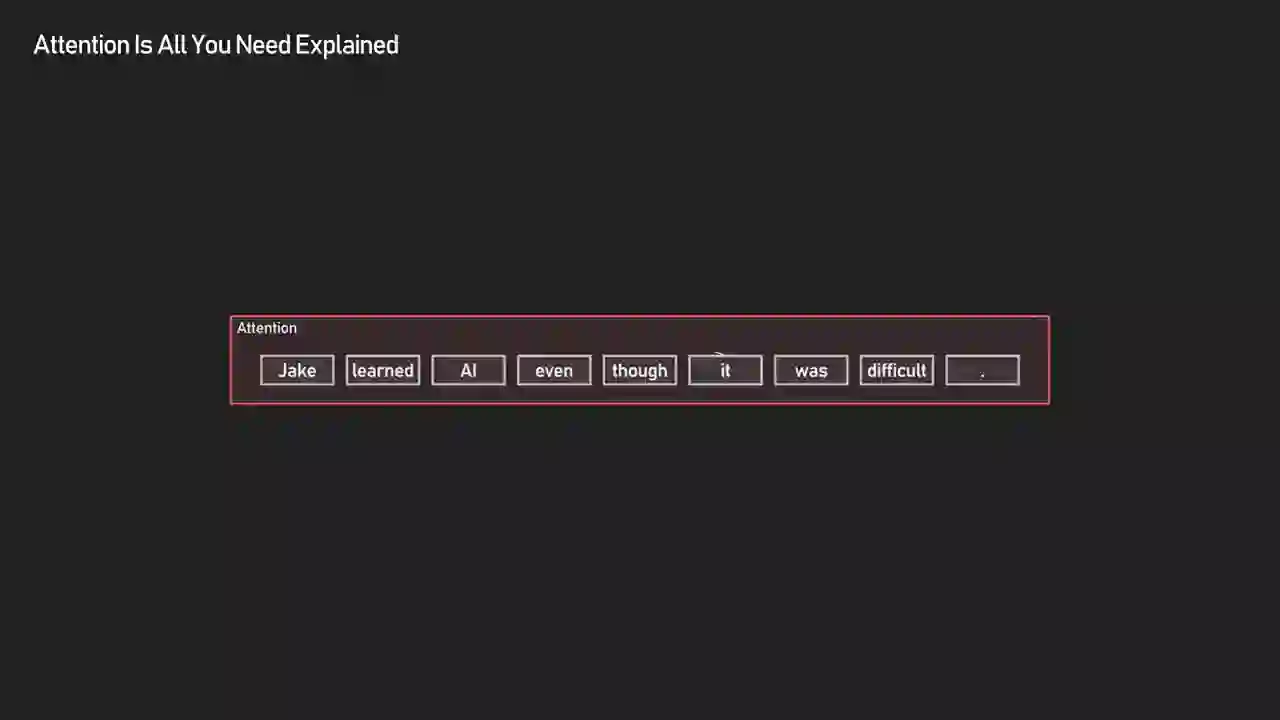
The token 'it' forms a query vector implicitly asking what concept am I referring to. The other tokens like Jake and AI each provide their keys describing what information they hold.
This is worth sitting with. Nobody programmed the network to know that "it" should look at "Jake" or "AI." Nobody even told it what a pronoun is. The Q/K/V projection matrices start out as random noise. They learn to encode linguistic structure because doing so reduces the next-token prediction loss. Attention patterns that help the model predict well get reinforced; patterns that don't, fade.
The mechanics from here are mechanical:
- Compute the dot product of the query from "it" against the keys from every token in the sentence.
- Divide by √d (where d is the head dimension) to keep the softmax from saturating — this is the "scaled" in scaled dot-product attention.
- Normalize the resulting scores with softmax, so they sum to 1.
- Use those normalized weights to compute a weighted sum of the value vectors.
- Replace "it"'s representation with that weighted sum.
Now "it" isn't just "it" anymore — it carries a blend of meaning from every token that was relevant, weighted by how relevant each one was.
This process gives us a new context-aware representation for each token, one that blends the most relevant information from the rest of the sequence.
One thing I learned the hard way in production: when debugging an LLM that gives a wrong answer despite having the right context in the prompt, the first diagnostic isn't "did the retrieval return the right chunk?" — it's "did the attention weights actually pick up the right chunk?" Anthropic's interpretability team has released several attention visualization tools that let you inspect this directly, and Hugging Face's BertViz does the same for open models. If your RAG system is hallucinating, attention inspection is the most underused debugging technique I know.
How Does the Math Stay Parallel?
The math stays parallel because the paper expresses attention as a single matrix operation. Instead of looping over tokens one at a time, Q, K, and V are packed into matrices and the attention output is computed as softmax(QKᵀ / √d) V — one giant batch operation that every GPU in the world was built for.
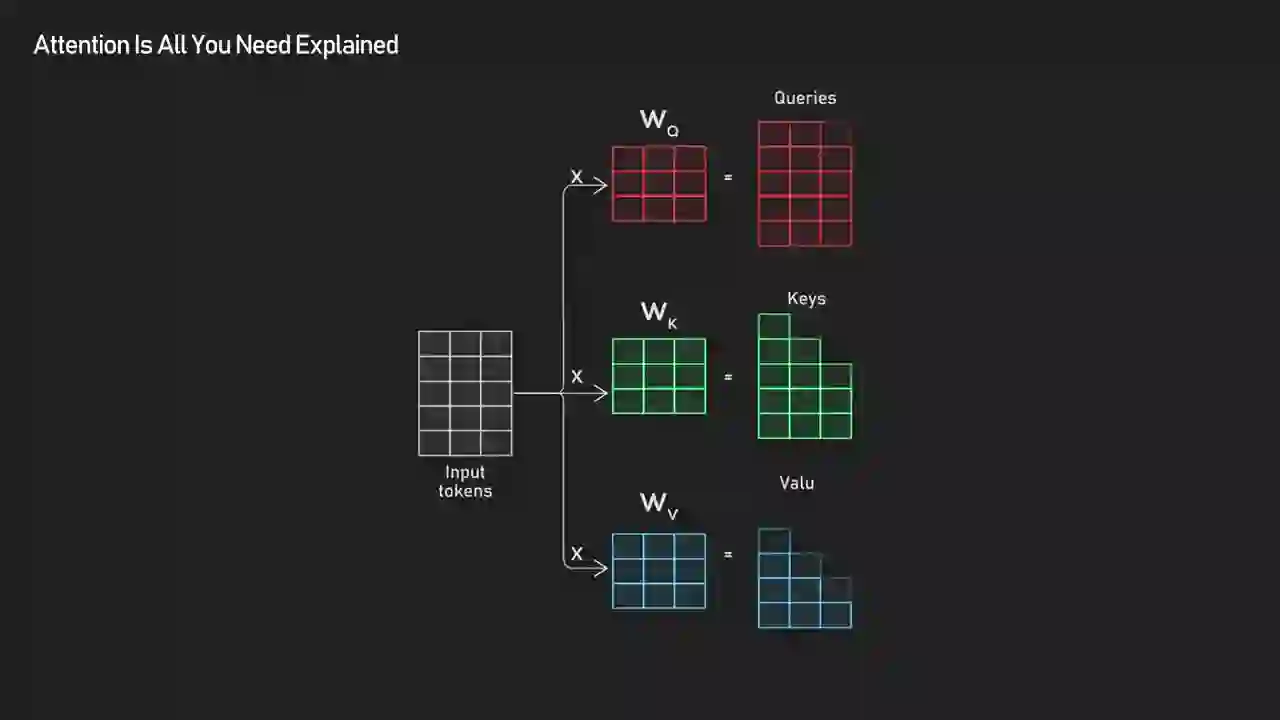
Instead of looping through tokens one by one, the model stacks all queries, keys, and values into matrices and performs these dot products and weighted sums simultaneously. This means every token communicates with every other token in a single set of parallel matrix operations, which is efficient and fully differentiable.
"Efficient and fully differentiable" is understated but important. Efficient means this runs at GPU-native speed. Differentiable means you can train it end-to-end with backpropagation — no hand-designed features, no hard attention tricks, no reinforcement learning hacks. Gradient descent does the entire job. That combination — GPU-efficient plus end-to-end trainable — is what unlocked scaling laws. Once you could train faster, you could train bigger. Once you could train bigger, models kept getting better in predictable ways, and the industry hasn't hit a clear ceiling yet.
The 2017 paper captured this precisely: Vaswani et al. showed "experiments on two machine translation tasks" where their models were "superior in quality while being more parallelizable and requiring significantly less time to train." "Significantly less time" has since meant an improvement of several orders of magnitude. The same paper that required a few days on 8 GPUs to beat the state of the art in 2017 would now take minutes on a single H100.
What's Changed in Transformers Since 2017?
The core idea — tokens talking to each other through Q/K/V projections — is unchanged. What's changed is almost everything around it: the attention kernel, the positional encoding, the normalization placement, the feed-forward design, and the way compute is distributed across expert networks. The transformers running in production in 2026 would be unrecognizable to someone who only read the 2017 paper.
Here are the modifications that matter in practice:
FlashAttention and Memory-Efficient Attention
The single biggest operational improvement since 2017 is FlashAttention, published by Tri Dao et al. at Stanford in 2022. Vanilla attention reads and writes the full N×N attention matrix to GPU HBM (high-bandwidth memory), which is the bottleneck — not the compute. FlashAttention keeps the attention computation in SRAM by tiling the computation, which eliminates most of the memory traffic and dramatically speeds up both training and inference.
Flash Attention 4 now hits 1,605 TFLOPs/s on NVIDIA Blackwell GPUs as of March 2026. For comparison, that's roughly 20x what the original FlashAttention achieved on A100s in 2022. If you're training any transformer larger than a few hundred million parameters in 2026 and you're not using FlashAttention, you're leaving 50-80% of your GPU budget on the floor.
Mixture of Experts (MoE)
The second biggest change is the shift from dense transformers to Mixture of Experts. In a dense model, every token passes through every parameter in the feed-forward layers. In an MoE model, each token is routed to a small number of "expert" sub-networks, activating maybe 5-20% of the total parameters per forward pass. This lets models reach much larger total parameter counts without proportional inference cost.
GPT-4 is estimated at 1.8 trillion parameters in a mixture-of-experts architecture, trained on roughly 13 trillion tokens. A dense model at that size would be economically impossible to serve. MoE is what made it viable.
Grouped-Query Attention and Multi-Head Latent Attention
LLaMA 2 introduced grouped-query attention (GQA), where multiple query heads share the same key and value projections. This cuts the KV cache memory requirements roughly in half with minimal quality loss — critical for inference on long contexts. DeepSeek went further with Multi-Head Latent Attention (MLA), compressing K and V projections into a shared low-rank latent space. The result: DeepSeek-V3 trained using "only 2.8 million H800 hours of training hardware time — about ten times less training compute than the similarly performing Llama 3.1."
That 10x efficiency gap is one of the loudest signals I know that the 2017 architecture still has meaningful optimization headroom. Every "transformers are dead" argument I've seen for the past year has been answered by a new architectural tweak that extends the plateau.
RoPE and Long-Context Extrapolation
I covered positional encoding earlier, but it's worth saying again here: the move from learned absolute positions to Rotary Position Embeddings (RoPE) was a small math change with enormous practical impact. RoPE is what lets modern LLMs extrapolate past their training context length with minimal quality degradation, which is how you go from a 4K context in early LLaMA to 128K in LLaMA 3.1 without retraining from scratch.
Hybrid Architectures
The newest and most controversial change is hybridization. Models like Mamba replace attention with state space models (SSMs), which have linear memory complexity and match transformer quality on many benchmarks. But pure SSM models struggle on some retrieval tasks — a problem that matters a lot in production systems that rely on Gemini File Search and similar retrieval-heavy workloads. The current compromise is hybrids: most tokens go through SSM blocks for efficiency, and a smaller fraction go through attention blocks for the tasks where attention genuinely helps. Sid Ab predicts that the winning hybrid ratio will settle around "70% of tokens processed by SSM experts and 30% routed to attention for deeper analysis."
Whether that's 2026, 2028, or 2030, the trajectory is clear: the pure transformer monoculture is fragmenting. But attention, in some form, is still sitting in the middle of every production stack.
How Does a Transformer Actually Learn to Pay Attention?
Training starts from random parameters and uses gradient descent to gradually shape the Q, K, and V projection matrices into patterns that minimize the loss. The attention heads that emerge are task-driven — nobody designs them, they grow.
At the very beginning of training, all the parameters are random. Therefore, all the representations are meaningless. The model has no idea what to look for or what to offer. But as training progresses, the parameters that produce the queries, keys, and values are optimized.
This is the part that still feels like magic even when you know the math. You take a randomly initialized 7-billion-parameter network, feed it a trillion tokens of text with a next-token prediction objective, and out the other side comes a model that understands coreference, syntax, code structure, and — at some scale threshold nobody can explain precisely — useful abstractions about the world.
What's happening during training, at the attention level, is specialization. Different attention heads end up tracking different linguistic phenomena. Researchers who probed BERT found heads that specialized in:
- Direct object tracking — verbs attend to the nouns they act on
- Coreference resolution — pronouns attend to their antecedents
- Syntactic dependencies — determiners attend to the nouns they modify
- Next-token patterns — attention heads that just look one position back
- Name-to-name relationships — "John said Mary thought..." chains
- Copy-from-context heads — which matter enormously for retrieval-heavy tasks
None of this was designed. It emerged from the data. If you want to go deeper, Anthropic's mechanistic interpretability research has traced specific attention circuits to specific behaviors in real production models. They've even identified "induction heads" — circuits that let transformers do in-context learning, which is the mechanism behind few-shot prompting.
Why Do Transformers Work Beyond Language?
Transformers generalize because attention is domain-agnostic. Any data you can represent as a sequence of elements that need to interact becomes a transformer problem — text, images, audio, video, code, proteins, graphs, and combinations of all of them.
It also extends beyond language to images, audio, and even code. Whenever data can be viewed as a sequence of elements that need to interact, transformers shine.
The evidence is everywhere at this point. A short list of where transformers displaced specialized architectures:
| Domain | Old Approach | Transformer Replacement |
|---|---|---|
| Computer vision | CNNs (ResNet, EfficientNet) | Vision Transformer (ViT), DINO, Swin |
| Speech recognition | RNN + CTC, LAS | Whisper (encoder-decoder transformer) |
| Protein folding | Rosetta, physics simulation | AlphaFold 2 (Evoformer uses attention) |
| Code generation | Seq2seq LSTMs | GPT-family decoder-only transformers |
| Video understanding | 3D CNNs | TimeSformer, VideoMAE |
| Time series forecasting | ARIMA, LSTMs | TimesFM, PatchTST |
| Graph reasoning | Graph Neural Networks | Plain transformers often match or beat GNNs |
| Multimodal AI | Separate encoders + late fusion | Unified transformer with cross-modal attention |
Each of these displacements happened for the same reason: the domain had some notion of "elements" (image patches, audio frames, amino acids, time steps), and attention gave a cleaner way to model how those elements influence each other than whatever came before.
The most recent expansion of that list is retrieval itself. Modern dense retrievers — the systems that underpin every production RAG pipeline, including ours at WebSearchAPI.ai — are fine-tuned transformers that embed queries and documents into a shared vector space. They've largely replaced the sparse BM25 and TF-IDF retrievers that dominated information retrieval for three decades. The same attention mechanism that helps a language model pick relevant words in a sentence also helps a retriever pick relevant documents in a corpus of billions.
If you remember just one thing, remember this. A transformer is a network that lets its inputs talk to each other. It's not magic, it's communication. And that's why attention really is all we need.
That's the line I'd tattoo on every ML whiteboard. When the architecture feels abstract — when you're lost in the soup of heads, layers, norms, and residuals — come back to it. Every design choice exists to make token-to-token communication efficient, parallel, and trainable. Everything else is implementation detail.
What Are the Real Costs of Running Transformers in Production?
The thing ByteByteGo's video doesn't discuss — and that every production engineer eventually runs into — is the economics. Transformers are mathematically elegant, but every attention head has a dollar sign attached. Understanding those costs changes a lot of architecture decisions you'll make when shipping LLM features.
Here's the rough shape of the numbers I deal with when serving transformer-based retrieval at WebSearchAPI.ai:
Inference cost per attention token is dominated by the KV cache, not the weights. For a decoder-only transformer doing autoregressive generation, memory bandwidth is usually the bottleneck. Each new token requires reading the full K and V cache for every prior token, at every layer. On a 70B model with a 32K context, that's roughly 20-40 GB of memory traffic per generated token. This is why you see so much effort going into KV cache compression, quantization, and grouped-query attention — they all attack the same bottleneck.
Training cost scales roughly quadratically with sequence length for standard attention. Doubling the context window from 4K to 8K doesn't double the cost — it quadruples it. This is why long-context models were rare before FlashAttention and other memory-efficient variants made it affordable. It's also why many production systems truncate or chunk long documents rather than feeding them whole.
Efficiency gains compound. When we migrated our retrieval backend to a multi-cloud architecture, a significant portion of the 30% operational cost cut came from picking GPUs with better attention throughput per dollar — not because we changed the model, but because different hardware shifts the price/perf curve differently depending on your sequence length and batch size. The hidden lesson: transformer inference is a hardware optimization problem as much as it is a model optimization problem.
The retrieval-attention tradeoff is real. One of the biggest production decisions I make is whether to feed an LLM more retrieved context (expensive attention, higher quality) or a smaller, better-filtered context (cheap attention, risk of missing the right chunk). Getting this wrong was how we used to hallucinate answers. Getting it right is how we cut hallucination by 45%. If you're building a RAG pipeline, the question "how much context can I afford in my attention layer" is as important as "what model should I use."
Open source hasn't closed the cost gap. Even with DeepSeek's impressive efficiency work, the gap between well-funded proprietary models and open-source ones remains measured in millions of GPU-hours. That concentration of compute is, in my view, the biggest long-term risk factor for the transformer era: the architecture is open, but the ability to train it at frontier scale is not.
What Happens When You Hit the O(n²) Wall?
The quadratic memory complexity of self-attention is the one limitation the entire research community has been trying to break since 2019. Here's how the attempts stack up.
| Approach | Complexity | Quality vs Vanilla | Production Use |
|---|---|---|---|
| FlashAttention | Still O(n²) compute, but O(n) memory | Identical | Universal in 2026 |
| Sliding window attention | O(n·w) where w is window size | Slightly worse on long-range tasks | Mistral 7B, some variants |
| Linear attention (Performer, Linformer) | O(n) | Noticeably worse on quality benchmarks | Rare in production |
| Sparse attention (BigBird, Longformer) | O(n·log n) | Task-dependent | Some specialized models |
| State space models (Mamba, S4) | O(n) | Competitive on many tasks, weaker on retrieval | Growing, mostly research |
| MoE with small attention | O(n²) per expert | Matches or beats dense | GPT-4, Mixtral, DeepSeek |
| MLA (DeepSeek) | O(n²) but compressed | Matches MHA at much lower cost | DeepSeek-V3 |
The honest summary: FlashAttention gave us back the memory budget, so even though the compute is still quadratic, the practical bottleneck moved from memory to FLOPs, which is a much easier fix. For most production workloads, the O(n²) wall has been delayed rather than eliminated — you can now serve 128K+ contexts, but the cost per token still grows sublinearly with context length only because of clever engineering, not because attention itself got cheaper.
What I watch most carefully is the Mamba-style hybrid direction. If someone finds a mix of SSM and attention that matches pure transformer quality on reasoning-heavy benchmarks while being meaningfully cheaper at inference, that's the moment a lot of production retrieval systems will rewrite their backends. As of April 2026, nobody has cleared that bar conclusively, but the research momentum is real.
Frequently Asked Questions
What is the "Attention Is All You Need" paper and why is it famous?
"Attention Is All You Need" is the 2017 paper by Vaswani et al. at Google that introduced the transformer architecture. It's famous because it replaced recurrent networks with a pure attention-based design, which made training far more parallelizable and set off the cascade of scaling that produced GPT, BERT, Claude, Gemini, and nearly every large language model in production today. The paper has been cited over 173,000 times — one of the most cited AI papers ever written — and is still the foundation that every frontier model builds on in 2026.
How is attention different from a convolutional or recurrent layer?
A recurrent layer processes tokens sequentially and passes hidden state forward one step at a time. A convolutional layer processes fixed-size local windows. Attention processes all tokens in parallel and lets each token directly attend to every other token in the sequence, regardless of distance. As ByteByteGo puts it, whether a key token appears two steps away or 200, attention reaches it in a single operation.
What are query, key, and value in simple terms?
Query, key, and value are three different projections of each input token, produced by multiplying the token's embedding by three learned weight matrices. The query represents what a token is looking for, the key represents what a token contains, and the value is the content a token will contribute if it gets picked. The attention score between two tokens is the dot product of one's query and the other's key. That score, normalized through softmax, becomes the weight on the value.
Why can't RNNs and LSTMs do what transformers do?
RNNs and LSTMs can, in theory, learn long-range dependencies, but they struggle in practice because information has to flow through every intermediate step, and gradients vanish or explode over long chains. They're also inherently sequential — step t can't start until step t-1 finishes — which makes them slow to train on GPUs. Transformers bypass both issues by replacing sequential state with parallel attention, so the gap between two related tokens is always one operation.
What is self-attention vs cross-attention?
Self-attention is when tokens in a single sequence attend to each other — this is what happens in every encoder block and in the first attention layer of every decoder block. Cross-attention is when tokens in one sequence attend to tokens in a different sequence, typically the decoder attending to the encoder's output. Cross-attention is how encoder-decoder transformers do translation: the decoder generates the output sequence while cross-attending back to the input sentence.
Are GPT, Claude, and Gemini all transformers?
Yes, all three are decoder-only transformers. They use the same core attention + feed-forward block structure described in the 2017 paper, scaled up to tens or hundreds of billions of parameters and trained on trillions of tokens. GPT-4 is estimated at 1.8 trillion parameters in a mixture-of-experts configuration. The differences between frontier models come from training data, positional encoding choices, normalization tweaks, and fine-tuning methods — not from the underlying architecture. Anthropic's Claude, OpenAI's GPT-4, and Google's Gemini are all, at their core, descendants of the same Vaswani et al. design.
What is multi-head attention and why does it matter?
Multi-head attention runs several attention operations in parallel, each with its own independent Q/K/V projections, then concatenates the results. Each "head" can learn a different type of relationship — one head might track syntactic dependencies while another tracks coreference. The original paper used 8 heads. Modern LLMs use dozens or hundreds. Multi-head attention is one of the most important design choices for model quality, and variants like grouped-query attention (GQA) and multi-head latent attention (MLA) are active areas of research focused on reducing its inference cost.
What is FlashAttention and why does everyone use it?
FlashAttention is a memory-efficient implementation of the standard attention operation that dramatically reduces the amount of GPU memory bandwidth required, without changing the mathematical output. It was introduced by Tri Dao and collaborators in 2022 and has since become the default kernel for training and inference in frameworks like PyTorch, Hugging Face Transformers, and vLLM. Flash Attention 4 achieves 1,605 TFLOPs/s on NVIDIA Blackwell GPUs as of March 2026, which is roughly 20x faster than the original 2022 implementation on A100s.
What are the known limitations of the transformer architecture?
The biggest practical limitation is that standard self-attention has O(n²) memory complexity in the sequence length — doubling the context window roughly quadruples the memory needed. FlashAttention has mostly solved the memory half of this problem, but the compute is still quadratic. This has driven research into more efficient variants like sliding window attention, linear attention, and state space models like Mamba. A second limitation is the massive compute required for training, which has concentrated frontier model development in a handful of well-funded labs. Neither limitation has been solved cleanly, but both are active research areas.
Will transformers be replaced by something else?
Probably not entirely, but likely hybridized. Pure state-space models like Mamba, S4, and RWKV can match transformer quality on many benchmarks while being linear in sequence length, but they lag on tasks that require precise information retrieval from long contexts — exactly the pattern that matters for grounding LLMs with Google Search results and other retrieval-heavy workloads. The most likely future is hybrid models where some layers use SSMs for efficient sequence mixing and others use attention for precise lookups. DeepSeek's Multi-Head Latent Attention, Mamba-Transformer hybrids, and architectures like Jamba are all examples of this direction. The transformer's core idea — learned, parallel, content-addressable sequence mixing — isn't going away.
Key Takeaways
- A transformer is a neural network that lets its inputs talk to each other through a communication layer called attention. ByteByteGo's framing is the one worth remembering — every implementation detail exists to make that communication efficient, parallel, and learnable.
- Attention replaced RNNs by solving two problems at once: it eliminated the sequential training bottleneck and it collapsed the distance between any two related tokens to a single operation. Long-range context stopped being an architecture problem.
- Query, Key, and Value are learned projections that encode "what am I looking for," "what do I contain," and "what will I contribute." The Q/K/V matrices start random and learn linguistic structure purely from next-token prediction loss.
- The matrix form of attention is what unlocked GPU scaling. Computing
softmax(QKᵀ / √d) Vin one shot replaced per-token loops with a single parallel operation, which is the reason transformers could grow from millions of parameters in 2017 to trillions in 2026 (GPT-4 alone is estimated at 1.8 trillion parameters in a mixture-of-experts configuration). - FlashAttention, RoPE, and MoE are the three biggest production changes since 2017. FlashAttention fixed the memory bottleneck. RoPE unlocked long-context extrapolation. Mixture-of-experts made trillion-parameter models economically viable.
- The same architecture works across modalities. Vision Transformers, Whisper, AlphaFold, and time-series models all use attention. Any domain where elements need to influence each other is a transformer problem — including modern dense retrieval for RAG systems.
- Encoder-only, decoder-only, and encoder-decoder are the three flavors. BERT is encoder-only. GPT, Claude, LLaMA, Gemini, and Mistral are decoder-only. T5 and the original 2017 model are encoder-decoder. Same attention mechanism, different wiring.
- O(n²) memory is mostly solved, O(n²) compute isn't. FlashAttention moved the bottleneck from memory to FLOPs, and clever engineering has pushed context windows past 1M tokens. But the core cost structure remains quadratic, which is why hybrid SSM/attention models and Mamba variants are the most-watched research direction in 2026.
- In production, cost matters as much as architecture. The choice between a longer context window and a tighter retrieval filter is often the dominant factor in whether an LLM feature makes economic sense. At WebSearchAPI.ai, cutting hallucination rates by 45% came as much from filtering tokens before attention as from any model choice.
This post is based on Transformers Step-by-Step Explained (Attention Is All You Need) by ByteByteGo.