Paperclip AI Agent Orchestrator: How to Hire and Manage a Team of AI Agents
Dotta demos Paperclip, the open-source agent orchestrator with 38,000+ GitHub stars. Learn agent configuration, the Memento Man mental model, agentic design patterns, and how to run a zero-human company.
Paperclip is an open-source AI agent orchestrator that hit 38,000 GitHub stars in under four weeks. Creator Dotta demoed how it turns AI models into a structured company with roles, budgets, and a heartbeat system that solves the stateless agent problem. This analysis covers the practical orchestration patterns, the unsolved security gaps in agent skill ecosystems, and what Paperclip's approach means for anyone coordinating multi-agent workflows in production.
Video Summary
Dotta, creator of Paperclip, joins Greg Isenberg (CEO of Late Checkout) for a 47-minute live demo of the open-source agent orchestrator that hit 38,000 GitHub stars in under four weeks. Dotta walks through the full workflow: creating a company goal, hiring a CEO agent, letting it draft a hiring plan and delegate tasks to specialized agents. The demo covers the heartbeat checklist system that solves the stateless agent problem, the skills.sh marketplace for extending agent capabilities, and the unsolved security gaps in agent skill ecosystems. The single most important takeaway: Dotta's "Memento Man" mental model frames AI agents as highly capable but amnesiac workers who need explicit context injection every time they wake up. Paperclip has attracted users from security firms to dentists to roofing companies, but has generated zero revenue.
Paperclip Key Insights
- AI agents are "Memento Man" — capable but amnesiac. Every time an agent starts a session, it has skills but zero context about who it is, what it's doing, or what happened before. The heartbeat checklist (fetch identity, read plan, check assignments, execute, store memory, report) solves this by re-establishing context at every wake-up.
Your AI agents are Memento Man. They wake up, they know how to fight, they know how to drive, they know how to take care of themselves and spend money, but they don't know who they are, they don't know where they are, they don't know what they're supposed to be doing.

- Taste is the last human moat. AI can execute anything except knowing what you actually want. Dotta and Greg agreed that encoding your values, brand standards, and quality criteria is the most important investment when working with agents.
AI can do everything except know your values. You actually have to become more aware of your values and find out how to communicate them back.

The concept of a good leader is very much someone who can clearly communicate their values and taste. Not much has changed except the vehicle. Instead of hiring employees, you're hiring agents.
-
Third-party agent skills have no security model yet. Skills run with full filesystem and network access. Dotta admitted "it's a real problem and it's something you have to be careful with. I don't think anyone's solved that." This is npm's supply chain problem with a larger blast radius.
-
QA loops prevent compounding errors. Each agent step at 95% accuracy across 10 steps yields only 60% end-to-end accuracy without checkpoints. Engineer-to-QA review loops act as error correction that resets the error probability.
-
Paperclip has 38,000 stars but zero revenue. Dotta was candid about this. The adoption is real — security firms, dentists, roofing companies — but stars aren't a business model. The long-tail non-technical users suggest the market is broader than developer tools alone.
-
Importable company templates are unproven. You can "acqui-hire" pre-built agent teams, but there are no evals, no benchmarks, and no quality guarantees. Dotta called it "completely unproven." This is the Docker Hub quality problem all over again.
-
Maximizer Mode removes human approval gates. The upcoming feature tells the CEO agent to accomplish a goal regardless of token cost. The risk: unbounded spend with no circuit breakers. Dotta didn't mention guardrails like max spend limits or anomaly detection.
I spend most of my time building infrastructure that connects AI agents to live web data at WebSearchAPI.ai. The coordination problem Dotta describes isn't theoretical. It's the thing that wakes you up at 3 AM.
The agentic AI market is projected to grow from $7.55 billion in 2025 to $199 billion by 2034, a 43.84% CAGR according to Precedence Research. That growth creates a coordination gap: more agents means more chaos unless you have tooling that sits above any single model.

What Is Paperclip and Why Does It Exist?
Paperclip is an open-source agent orchestrator for managing teams of AI agents. You define business goals, hire agents, approve their work, and track token spend from a single dashboard. It launched on March 2, 2026, and has already passed 38,000 GitHub stars.
I built Paperclip because I was using Claude Code to build my companies and I would have 20 or 30 Claude Code windows open all at once. I couldn't remember what any of them were working on. I would set them to run over the weekend and come back and had no idea what anyone did.
That pain point maps directly to what I see in production. At WebSearchAPI.ai, we run multiple agent pipelines that each trigger sub-agents for data extraction, ranking, and validation. Without centralized tracking, a single query that fans out to three sub-agents can cost 10x what you'd expect, and you won't know until the invoice arrives. Paperclip's dashboard-level visibility into per-agent token spend is the feature I'd want first.
What makes Paperclip different from the growing list of agent frameworks is its "bring-your-own-bot" philosophy. It works with Claude Code, Codex, OpenCode, Cursor, and any model on OpenRouter. As Dotta put it, "all the entrepreneurs that I know are using lots of different models because they all have such a different personality."
This model-agnostic approach matters because in practice, different tasks genuinely perform better on different models. We've found that Claude handles nuanced extraction tasks better, while faster models work fine for structured data formatting. An orchestrator locked to one provider forces you into a single model's strengths and weaknesses.
How Does Paperclip Compare to Other Agent Orchestrators?
Paperclip enters a crowded field. Here's how it stacks up against the major open-source alternatives:
| Framework | GitHub Stars | Model Flexibility | Visual UI | Built-in Memory | Skill Ecosystem | License |
|---|---|---|---|---|---|---|
| AutoGen (Microsoft) | 56.4K | Multi-model | AutoGen Studio | Stateful agents | Tool plugins | MIT |
| CrewAI | 47.5K | Multi-model via LiteLLM | CrewAI+ (paid) | Role-based memory | Tool & task system | MIT |
| Paperclip | 38.4K | Bring-your-own-bot | Built-in React UI | PARA file-based | skills.sh marketplace | MIT |
| LangGraph (LangChain) | 27.9K | Multi-model | LangSmith (paid) | Checkpointer system | LangChain tools | MIT |
| OpenAI Swarm | 21.3K | OpenAI only | None | No built-in | Handoff-based | MIT |
| Agency Swarm | 4.1K | OpenAI SDK | Gradio UI | Shared state | Agency structure | MIT |
The distinction that matters: most frameworks are libraries you code against. Paperclip is a runtime you interact with through a UI. AutoGen and CrewAI give you Python primitives to build workflows. Paperclip gives you a dashboard where you "hire" agents and watch them work. That's a fundamentally different user experience, aimed at founders and operators rather than engineers building custom pipelines.
From an infrastructure perspective, the PARA-based file memory system is smart but limited. When we handle state management for our retrieval agents, we use distributed stores with TTL-based expiration and conflict resolution. File-based memory works for single-machine setups but will need rethinking as Paperclip scales to remote and concurrent agent deployments.
How Do You Set Up Agents in Paperclip?
The setup flow follows a three-step pattern: define your company goal, create your first agent (the CEO), and let the CEO draft a hiring plan.
After you write down what you want your company to do, you create your first agent. Paperclip right now best works when it's on your local machine and especially if you already have something like Claude Code or Codex installed.
For the demo, Dotta picked a startup idea from Greg's Idea Browser — a finance app called "Moolah" that builds money habits in three minutes a day. He pasted the description, created a CEO agent running Claude Opus, and let it generate a hiring plan.
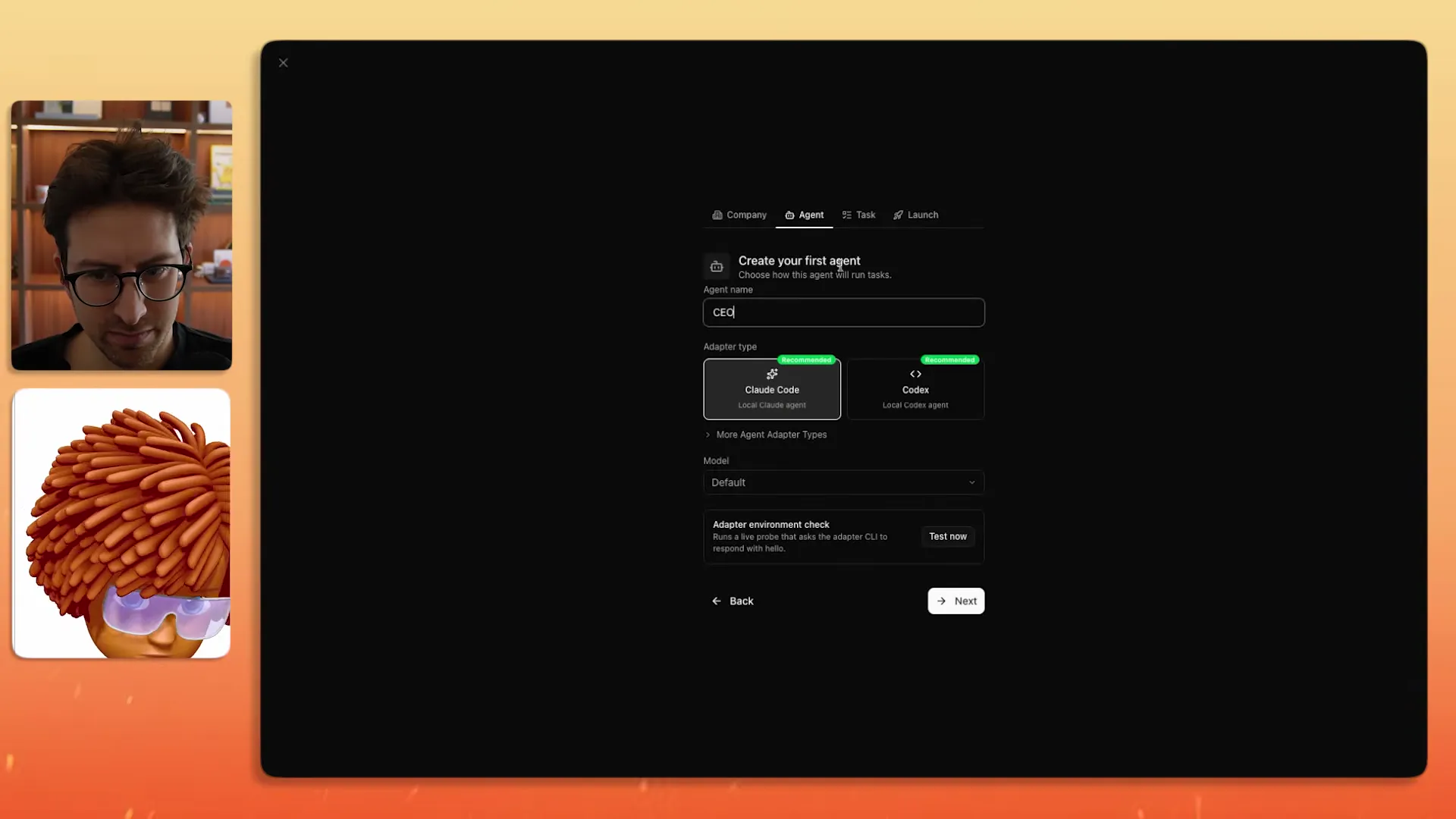
Within minutes the CEO had created a founding engineer, broken the roadmap into concrete tasks (scaffolding, CI/CD, user auth, core daily loop), and started delegating work. Each task can only be handled by one agent at a time, preventing the conflict of agents stepping on each other.
This single-assignment constraint is a deliberate design choice. In distributed systems we call this "exclusive locking" — only one process can own a resource at a time. It prevents merge conflicts and duplicate work, but it also means agents can't collaborate on the same file simultaneously. For a v1, that's the right trade-off. Collaborative editing (like Google Docs for agents) is an open research problem.
A practical tip from the demo: Paperclip recommends a Frontier model for your CEO agent but allows cheaper models (or even free ones from OpenRouter) for other roles. This mirrors how real engineering orgs allocate resources — senior architects make design decisions while junior engineers handle implementation.
What Is the "Memento Man" Mental Model for AI Agents?
This was the most quotable insight from the entire conversation. Dotta compares AI agents to the protagonist of the movie Memento.
Your AI agents are Memento Man. They wake up, they know how to fight, they know how to drive, they know how to take care of themselves and spend money, but they don't know who they are, they don't know where they are, they don't know what they're supposed to be doing.
The solution is a heartbeat checklist — a set of instructions that runs every time an agent wakes up:
- Fetch your identity (confirm who you are)
- Read today's plan
- Check your assignments
- Break work into tasks
- Extract and store memory
- Report what you accomplished
I've seen this exact pattern in production, just with different names. At WebSearchAPI.ai, our retrieval agents are stateless services with external state stores and health checks. The heartbeat checklist is a liveness probe combined with a context injection step. Every time an agent spins up, it reads its identity from a config store, checks a task queue, executes, and reports back. Dotta is describing Kubernetes-style orchestration applied to LLM agents — and that's the right mental model.
The memory system uses Tiago Forte's PARA method (Projects, Areas, Resources, Archives), with the implementation contributed by Nat Eliason. This is clever because PARA provides a natural categorization that maps to how agents need to access information: active projects vs. reference material vs. archived context.
When agents make mistakes, Dotta's fix is surprisingly manual: go into the persona prompt and add a rule. "When it does something you don't like, you come in here and you say rule, make sure you remember to set a success condition for every task." This iterative prompt refinement is the current state of the art for agent quality control, but it doesn't scale. With 10 agents, you can hand-tune prompts. With 100, you need automated feedback loops. That's one place where Claude Code skills can help — they let you encode repeatable quality patterns that agents can reference without manual prompt editing.
How Do Skills Extend What Agents Can Do?
Skills are installable capability packages that give agents new abilities. Dotta demonstrated installing the Remotion skill so a video editor agent could produce animated content.
Another key way that you might want to configure your agent would be with skills. The best way to find skills would be skills.sh.
My question here is how do you know you're not installing skills that have bad stuff in it? Malicious stuff.
It's a real problem and it's something you have to be careful with. I don't think anyone's solved that.
Greg's security question is the one I'd have asked first. Third-party skills run with the same permissions as your agent, which often means full filesystem and network access. The current trust signals are directional at best: security audit badges on skills.sh and GitHub star counts. As Greg pointed out, "just because it has a lot of GitHub stars doesn't mean it's 100% secure, but it does give you directional data."
This is the same supply chain vulnerability we've seen play out in npm, PyPI, and every other package ecosystem. The difference with agent skills is the blast radius is larger: a malicious npm package can exfiltrate env vars, but a malicious agent skill can read your entire codebase, make API calls on your behalf, and modify files. I've written about building web search agent skills that follow a sandboxed approach — defining explicit permission boundaries for what a skill can access. That pattern needs to become the default, not the exception.
We're likely to see skill registries evolve toward something like npm's security model: automated vulnerability scanning, verified publishers, and dependency auditing. But today, you're trusting code you didn't write with full access to your machine. Treat skills the way you'd treat a new hire: verify references before giving them the keys.
How Do You Get Top-Quality Output from AI Agents?
Greg asked the million-dollar question: if you hire a video editor agent with the Remotion skill, how do you ensure it produces top 1% work?
You can never get around the idea that you have to provide that context. Ultimately Paperclip is not going to on its own write that context for you.
Dotta's answer boils down to two investments:
-
Brand guides — Write down your visual identity, tone, style, and success criteria. Store them where agents can reference them.
-
QA loops — Hire a QA agent that reviews work before it ships. The engineer builds, QA checks. This is especially important for web apps where you need to verify things actually work visually.
This matches what I've learned running AI pipelines in production. When we reduced hallucination rates by 45% in our RAG system, the fix wasn't a better model — it was better evaluation criteria. We wrote explicit ranking rules that defined what a "good" extraction looks like, then built automated checks against those rules. The model didn't improve. Our definition of "correct" got sharper.
The same principle applies to agent orchestration. A brand guide is really an eval rubric for creative work. The more specific your criteria ("buttons must be 44px tap targets with 8px border radius"), the more consistently agents will hit the mark. Vague instructions ("make it look professional") produce vague results.
How Does Token Spend Tracking Work?
Paperclip tracks every token spent and every task completed. During the demo, the monthly spend showed $0 because Dotta was using his Claude Code subscription rather than pay-per-token API credits.
One of the things you'll notice is that our monthly spend right now is $0 even though we've been doing all this work. Part of that is because I'm using my Codex subscription or Claude Code subscription.
If you connect agents via OpenCode or pure API credits, you get real dollar tracking. This solves a problem I see constantly: when you're running multiple agent pipelines, you have no idea how much an individual task costs until the monthly bill arrives.
For context, running a multi-agent coding task with a Frontier model can easily consume 500K-1M tokens per session. At current Anthropic API pricing, that's $1.50 to $15 depending on the model and input/output ratio. Multiply by 10 agents running daily and you're looking at $450-$4,500/month just in inference costs. Subscription-based access (Claude Code at $200/month for Max) can be dramatically cheaper for sustained usage, which is why Dotta's $0 spend makes economic sense.
The cost transparency isn't just nice-to-have. It's what lets you make rational decisions about which tasks justify Frontier models and which can run on cheaper alternatives.
What Are Agentic Design Patterns and Why Do QA Loops Matter?
Dotta addressed why one-shotting an entire startup with AI always falls apart after the first 30 minutes.
Everybody who's tried to one-shot a new startup with AI, you realize it's super fun for the first half an hour and then it just kind of falls apart. There are a lot of new patterns coming out around agentic design patterns.
He referenced OpenAI's writing on "harness engineering" — their term for structuring how agents interact with one another to get better results than single-shot approaches. The most basic pattern is an engineer-to-QA review loop: after the engineer creates something, QA reviews it.
During the demo, Dotta spotted a misaligned UI element (pills with different heights) and created an issue: fix it, then pass to QA to verify with a screenshot. This human-in-the-loop at the design level is still necessary because, as he put it, running a zero-human company means you "cannot be managing your apps at that level."
I think about this in terms of error propagation. In a multi-step agent pipeline, each step has some probability of introducing an error. If each step is 95% accurate and you chain 10 steps, your end-to-end accuracy drops to about 60%. QA loops act as error correction checkpoints, resetting the error probability before it compounds. That's why they matter more in orchestrated workflows than in single-shot interactions — the math of compounding errors demands it.
This is also why Paperclip's approach of having agents work on one task at a time is valuable. It creates natural checkpoints where QA can intervene. Compare this to AutoGen's conversation-based approach where agents discuss in threads — it's harder to insert quality gates into a flowing conversation than into a discrete task queue.
Why Is Taste the Last Human Moat?
This was the philosophical peak of the conversation. Even frontier models like GPT-5.4 and Claude Opus 4.6 lack personal taste.
AI can do everything except know your values. And so you actually have to become more aware of your values and find out how to communicate them back.
Which is even in a pre-AI era, the concept of a good leader, of a good CEO, of a good founder is very much someone who can clearly communicate their values and taste. Not much has changed except the vehicle to doing it has changed. Instead of hiring employees, you're hiring agents.
This resonates with something I've observed building search APIs. The hardest part of our retrieval pipeline isn't the technology — it's defining what "relevant" means for each use case. Two customers can search for the same query and need completely different ranking criteria based on their domain. The model is the execution engine. The human's judgment about what constitutes a good result is the irreplaceable input.
The practical implication: invest time writing skills that capture your specific preferences. A generic "web search" skill will give you generic results. A skill that encodes your ranking logic, your data freshness requirements, and your quality thresholds will produce work that reflects your standards. That's where the moat is — not in the model, but in the encoded taste layer above it.
How Many Agents Run the Paperclip Project Itself?
Dotta uses Paperclip to build Paperclip. His org chart includes:
| Role | Agent Type | Purpose |
|---|---|---|
| CEO | Claude Opus | Strategic direction, planning |
| CTO | Claude Code | Technical architecture |
| Cursor Coder | Cursor | Frontend development |
| Claude Coder | Claude Code | Backend development |
| QA Engineer | Claude + Agent Browser | Visual testing, verification |
| Evals Engineer | Claude | Performance reviews on agents |
| UX Designer | Claude | Design with taste context |
| CMO | In progress | Marketing coordination |
| Content Strategist | In progress | Blog, Discord updates |
The QA engineer uses both the Claude browser and a skill called "Agent Browser" that provides web access faster than Chrome. As Dotta noted, if you have used Chrome with Claude Code before, "it pops up a Chrome window and takes over your computer and if you click on it you mess it up."
The evals engineer is the role I find most interesting. It's focused on agent performance reviews — looking at past issues, analyzing feedback patterns, and helping agents learn from repeated mistakes. This is meta-orchestration: an agent whose job is to make other agents better. We use a similar pattern for monitoring our search API quality, where automated evaluators flag degraded results before users notice. The concept of automated workflow skills feeding back into agent improvement loops is where this space is heading.
How Do Routines Automate Recurring Agent Tasks?
Routines are templates for issues that repeat on a schedule. Dotta demonstrated creating a routine that reads the day's GitHub changes and crafts a Discord message celebrating community contributors.
One of the things that we just added this week is the idea of routines. So a routine is actually almost like a template of an issue. It's an issue that you're going to rerun over and over every day.
He set up a trigger for 10 AM daily, assigned it to the content strategist agent, and instructed it to read the GitHub changes for the last 24 hours, craft a community-formatted Discord message, and specifically call out community members whose PRs were merged.
The tracking still applies: every routine execution logs tokens spent, what the agent found, and what it produced. "Instead of having some job that runs in the background that you have no tracing over, every single task that Paperclip does, you can go back and look and make it better."
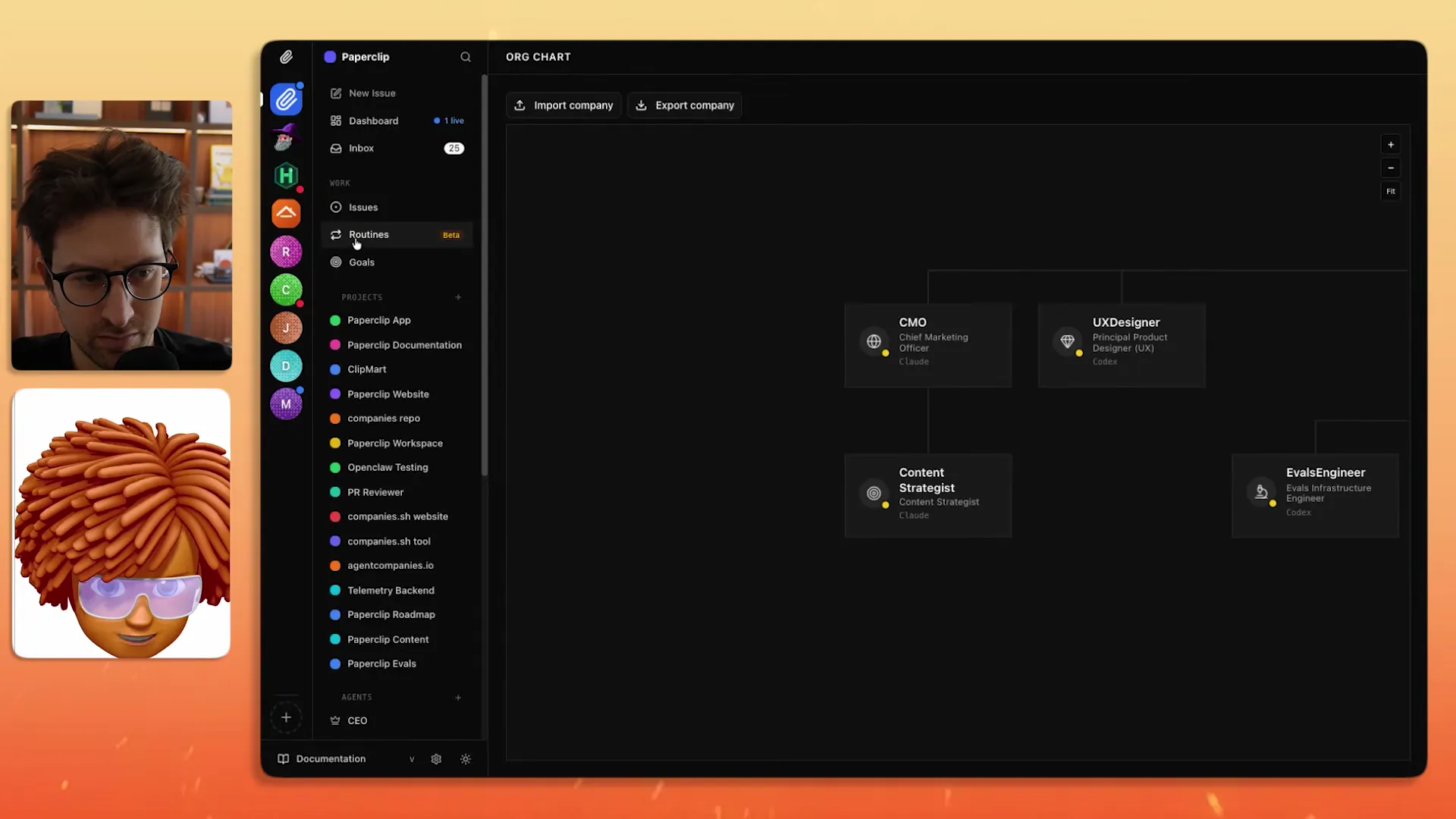
This is where Paperclip starts to overlap with tools like Zapier and n8n, but with a meaningful difference. Traditional automation tools execute deterministic workflows: if X then Y. Paperclip's routines execute via an LLM agent that can adapt to context. If the GitHub changelog is empty, it doesn't send a blank message — it can decide there's nothing worth reporting. That judgment layer is what separates agent-driven automation from rule-based automation.
Who Is Using Paperclip Today?
Despite being less than four weeks old, Paperclip has attracted diverse users beyond the expected startup crowd:
- Security review companies using Paperclip to manage automated security audits for clients
- A dentist organizing foundation work and family management
- Roofing companies exploring AI sales agents that cross-reference satellite imagery with hail data to find leads
- Marketing firms setting up agent teams for existing businesses
As much as the tagline is run a zero-human company, we're finding people who already have a marketing firm, they're setting up agents. Paperclip has the most GitHub stars but hasn't made any revenue yet, so I would say the companies that are making money are maybe more successful arguably.
The honesty about revenue is refreshing. Stars and traction are not the same as a sustainable business. The long-tail use cases — dentists, roofers, marketing firms — suggest agent orchestration is finding product-market fit in places nobody predicted. These aren't technically sophisticated users building custom pipelines. They're operators who want a dashboard for managing AI workers the same way they'd manage human teams.
That adoption pattern tells you something about where the market is headed. The $52.62 billion AI agents market projection from MarketsandMarkets won't be driven by developer tools alone. It'll be driven by non-technical users who need coordination layers above the models. Paperclip is positioned for that user, which is a different bet than what AutoGen and LangGraph are making.
What Are Shareable and Importable Companies?
One of Paperclip's most forward-looking features is the ability to import and export entire company configurations — agents, skills, and organizational structure included.
So one of the things that we are shipping probably by the time people are watching this is the ability to import and export companies.
Dotta showed three examples:
- Gary Tan's G-Stack — A set of skills where you can do office hours talking to Gary's engineering style
- Agency Agents — A repository with over 100 agents and 60,000 GitHub stars that can be imported into Paperclip with all skills intact
- Don Cheetos Game Studio — A full game development org with creative director, producer, technical director, and asset creation skills
The import mechanism references remote repos rather than copying skills locally, so you automatically receive upgrades. Greg framed the concept well: "I can go and hire agents from scratch, or I can acqui-hire a proven team and bring them into my Paperclip instance."
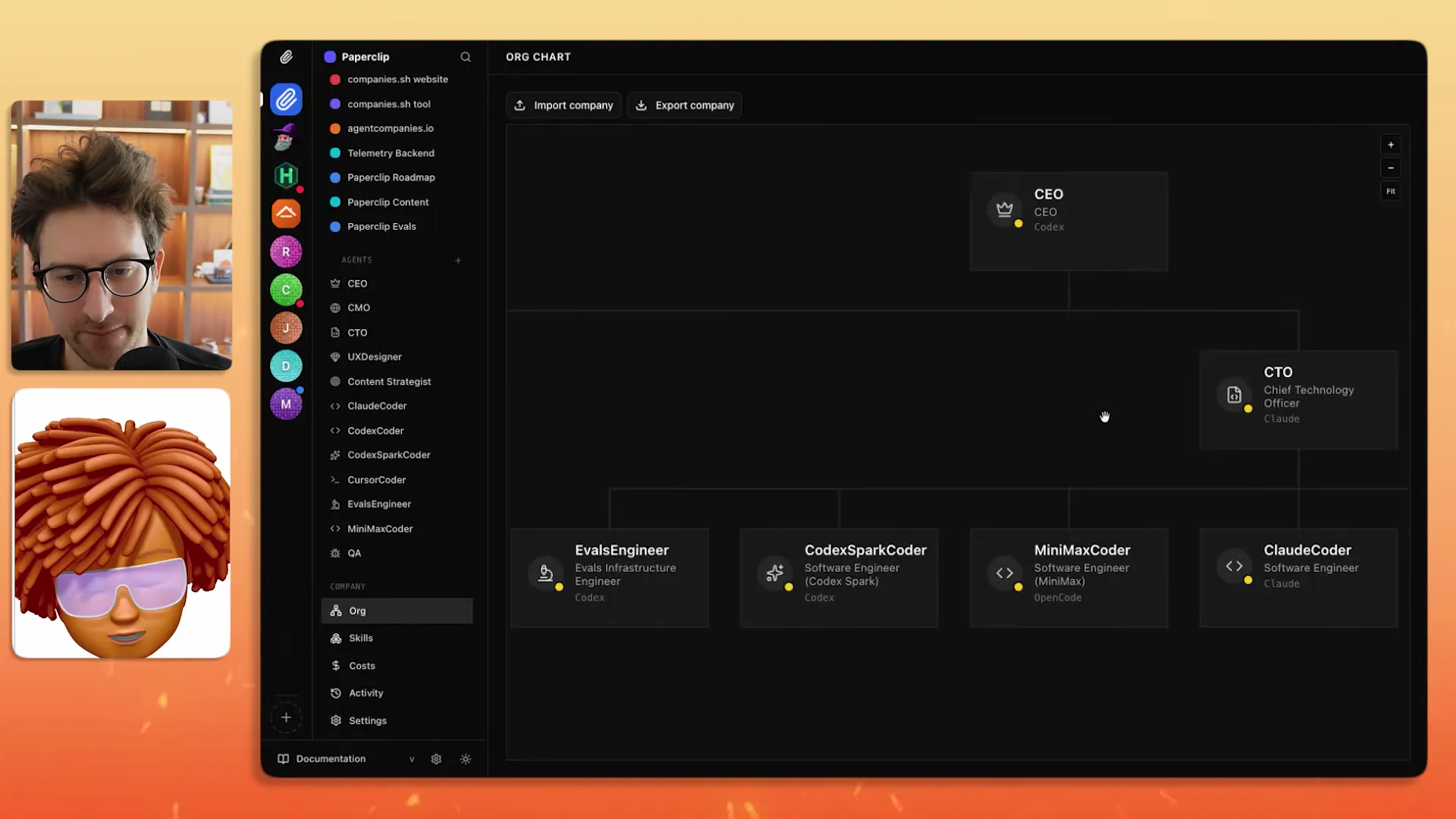
The obvious question is whether these pre-built teams actually work. Dotta was candid: "It's just completely unproven at this point. There's never been a piece of software like Paperclip where you could go to these repos that have 100,000 GitHub stars and 300 agents and there's no evals for them."
This is the Docker Hub problem all over again. Docker made it trivially easy to share container images, and the ecosystem exploded. But the quality problem took years to address: unvetted images, security vulnerabilities, abandoned builds. Paperclip's importable companies will face the same challenge. The future isn't just shared agent templates — it's tested, evaluated templates with published benchmark results. Until then, import with caution.
What Is Maximizer Mode?
Maximizer Mode is an upcoming feature where you tell the CEO agent to accomplish a goal regardless of token cost. Instead of pausing for approval at every step, the CEO ensures someone is always working.
My favorite feature that we're working on right now is called Maximizer Mode. You basically don't really care that much about token spend and you're saying I want to make sure that the CEO makes sure someone is working all the time. You do whatever it takes.
This shifts Paperclip from an approval-based workflow to an outcome-based one. You define the end state ("this game is playable and you say it's completely done") and the system figures out staffing, sequencing, and execution.
The risk here is obvious: unbounded token spend with no human checkpoints. Based on what I've seen with runaway agent loops in our own testing, you can burn through thousands of dollars of API credits in hours if an agent gets stuck in a retry loop. Maximizer Mode needs strong circuit breakers — max spend limits, time bounds, and anomaly detection. Dotta didn't mention those guardrails in the demo, but they'll be essential before this feature ships to production users.
Will Agent Orchestrators Survive the Bitter Lesson?
Dotta addressed the existential question: will the underlying models get good enough that you don't need custom orchestration software?
If we're going to find that AI takes a lot of people's jobs, you still need a piece of software that helps manage the jobs that are left. If I'm managing 10 AI agents or 100, you still need software that's going to help you manage the taste and the organization at scale.
The argument is that Paperclip operates at a higher abstraction level than any single model. It isn't fixed to one agent. As models improve, the agents get better, but the need for coordination, accountability, and taste management remains. Paperclip's co-founders — Dotta, Devin Foley (early Slack and Figma), and Scott Tong (head of product design at Pinterest) — are betting that orchestration is a durable layer.
I think Dotta's right about the coordination layer surviving, but wrong about the specific form factor. Today's agent orchestrators look like project management dashboards because that's the metaphor we know. The next generation will look more like declarative infrastructure — you'll define desired outcomes and constraints (budget, quality, timeline) and the orchestrator will figure out staffing and sequencing automatically. We're already seeing hints of this in Maximizer Mode.
The real question isn't whether orchestrators survive. It's whether the coordination layer gets absorbed into the model providers themselves. Anthropic, OpenAI, and Google are all shipping multi-agent capabilities. If Claude can natively coordinate sub-agents with built-in memory and tool use, the value of a standalone orchestrator shrinks. Paperclip's defense is the same as any middleware: it works across providers. As long as enterprises want to avoid single-vendor lock-in, there's room for an independent coordination layer.
Key Takeaways
- Paperclip is a bring-your-own-bot orchestrator that works with Claude Code, Codex, OpenCode, and any model on OpenRouter. It hit 38,000 GitHub stars in under four weeks, making it one of the fastest-growing open-source AI projects of 2026.
- AI agents are "Memento Man" — they wake up capable but with zero context. Heartbeat checklists, persona prompts, and file-based memory (using the PARA method) keep them effective between sessions.
- The biggest quality lever is encoding your own taste into agent skills and brand guides. AI can execute anything except knowing what you actually want. Invest time in building custom skills that capture your specific standards.
- Agentic design patterns like engineer-to-QA loops prevent compounding errors across multi-step workflows. Each step at 95% accuracy across 10 steps yields only 60% end-to-end accuracy without checkpoints.
- The agentic AI market is projected to reach $199 billion by 2034 (Precedence Research), with the coordination layer becoming the critical missing piece as organizations deploy more agents.
- Importable company templates point toward a future where you "acqui-hire" proven agent teams. But like early Docker Hub, quality and security evaluation infrastructure is missing.
- Maximizer Mode shifts from approval-based to outcome-based orchestration — but needs circuit breakers to prevent runaway spend.
Frequently Asked Questions
Is Paperclip free to use?
Paperclip itself is free and open-source under the MIT license. You install it locally and run it from your machine. The cost comes from the AI models your agents use — either through subscriptions (Claude Code Max at $200/month, Cursor Pro) or pay-per-token API credits via OpenRouter or direct provider APIs.
What AI models does Paperclip support?
Paperclip supports any model that can receive a "heartbeat" — its term for periodic context injection. Out of the box, it integrates with Claude Code, Codex, OpenCode, Cursor, and any model available on OpenRouter (which includes GPT-4, Claude, Gemini, Llama, Mistral, and dozens of others). The bring-your-own-bot approach means you're not locked into a single provider.
How is Paperclip different from CrewAI or AutoGen?
The primary difference is the abstraction level. CrewAI and AutoGen are Python frameworks — you write code to define agents, tasks, and workflows. Paperclip is a UI-driven application — you "hire" agents through a dashboard, assign them tasks, and manage them like employees. CrewAI focuses on role-based collaboration, AutoGen on multi-agent conversations. Paperclip focuses on organizational structure: org charts, budgets, accountability, and token tracking. If you're a developer building a custom pipeline, CrewAI or AutoGen gives you more control. If you're a founder managing AI workers, Paperclip's dashboard is more accessible.
How much does it cost to run AI agents with Paperclip?
Costs vary based on model choice and usage intensity. Using subscription plans (Claude Code Max at $200/month) gives you unlimited usage for that model. Using API credits, a single multi-agent coding session can consume 500K-1M tokens, costing $1.50-$15 depending on the model. Running 10 agents daily on API credits could cost $450-$4,500/month. Paperclip's token tracking dashboard helps you monitor and optimize these costs across all agents.
What is the Memento Man mental model for AI agents?
Coined by Dotta, "Memento Man" compares AI agents to the protagonist of the movie Memento — someone who is highly skilled but has no memory of who they are or what they're doing. Every time an agent starts a new session, it "wakes up" with capabilities but no context. The solution is a heartbeat checklist: a sequence of steps (read identity, check plan, fetch assignments, execute, store memory, report) that runs at the start of every session to reestablish context.
Can Paperclip run without coding knowledge?
Mostly yes. The dashboard UI lets you create companies, hire agents, assign tasks, and monitor progress without writing code. Installing skills from skills.sh is also UI-driven. Where coding knowledge helps: customizing agent persona prompts, writing brand guides, creating custom skills, and debugging agent behavior when things go wrong. The more technical you are, the more you can fine-tune. But the basic workflow — goal → CEO → hire → execute → review — is accessible to non-technical users.
Is Paperclip secure for business use?
Paperclip runs locally on your machine, which means your data stays on your hardware. The security concern is with third-party skills: they run with the same permissions as your agents, which often means full filesystem and network access. There's no sandboxing or permission system for skills yet. Dotta acknowledged this is unsolved. For business use, audit any skills before installing them, prefer skills from verified publishers on skills.sh, and avoid giving agents access to production credentials or sensitive data until the security model matures.
This post is based on Paperclip: Hire AI Agents Like Employees (Live Demo) by Greg Isenberg.