The AI-Native Company: Garry Tan and Diana Hu's CS153 Playbook for One-Person Frontier Startups
Garry Tan and Diana Hu's Stanford CS153 lecture on agentic primitives — skills, resolvers, Skillify, evals, and three-layer memory — and how AI-native companies hit $1–2M revenue per employee in 2026.
Garry Tan, President and CEO of Y Combinator, and Diana Hu, General Partner at YC, returned to Stanford for CS153 Frontier Systems. The thesis: the unit of production has collapsed. A six-person team can now hit $10M in revenue, and the YC portfolio is averaging 10% week-over-week growth — a bar only Airbnb used to clear. This post unpacks the agentic primitives they teach and how those primitives map directly onto company structure.
Video Summary and Key Insights
📺 Watch the full 47-minute lecture on YouTube: Stanford CS153 — The AI Native Company. Stanford Online has disabled third-party embedding, so this post shows 10-second clips from the lecture inline at each major section. Click through for the complete talk.
Class host Anjney Midha (co-founder of AMP PBC, co-instructor of CS153) opens by drawing a line from YC's SAFE document in 2011 — venture capital's "electrical grid" standardization moment — to the new standardization happening in 2026 at the code-and-markdown layer. Garry Tan and Diana Hu then split the lecture. Garry covers the agentic primitives he's learned building gstack and gbrain in five days of vibe-coding what used to take him two years and ten people. Diana extends those primitives into a theory of the AI-native company: an open-loop org becomes a closed-loop system when every workflow produces artifacts an agent can read.

Key Insights:
- Garry rebuilt his Twitter-acquired startup Posterous in five days on a $200 Claude Code Max plan. In 2008 the same product took 10 hires, ~$4M, and two years. His new project gstack hit 87,000 GitHub stars in two months. Total across gstack + gbrain: more than 100,000 stars, 15,000 daily active users, 305,309 skill invocations since January.
I was able to create all the software we made over two years with 10 people and all that capital, but me with a $200-a-month Claude Code Max plan. It didn't take like two years. It took about five days.

-
A six-person team in 2026 can hit $10M in revenue. Diana's portfolio data: YC companies have gone from zero to tens of millions in a single year — Series B traction in months, not the four-to-five-year timeline that used to define it.
-
The new agentic primitives map directly onto the company. Skills are employees. Resolvers are the org chart. The brain repo is internal process. CheckResolvable is audit and compliance. LLM-as-judge eval triggers are performance reviews. The org chart and the agent graph are now the same artifact.
-
Skillify is a 10-step ritual, not a one-shot save. When Garry tells an agent to "Skillify," it has to write the code, write unit tests, write LLM evals for the skill, write an integration test, add a resolver trigger in
agents.md, run an LLM-as-judge eval, run CheckResolvable to avoid duplicate skills, run an end-to-end smoke test, and finally pick a schema and a home in the memory repo. Two of those ten steps are the actual code.
Look at all these steps. Writing the skill and writing the code is only two out of the 10 steps. All the rest is making sure that this messy system, that is kind of more like a human system than perfect beautiful beam-of-light code, can still work.
-
gbrain is a three-layer memory system on top of Andrej Karpathy's knowledge wiki. Pure grep fell over, so Garry layered vector search, RRF fusion, backlinks, and a typed knowledge graph on top. He's now adding an epistemology layer that tracks whether a fact is a hunch, a belief held by a specific person, or world knowledge — so the system can spot a founder's contrarian bet years before it becomes consensus.
-
Open-loop companies leak; closed-loop companies compound. Diana's framing borrows from PID control theory. In an open-loop org, information lives in DMs, unwritten meetings, and vibes — agents see roughly 10% of company state. In a closed-loop org, every workflow produces an artifact (Linear ticket, GitHub commit, Slack channel post, recorded sales call) that an agent can read. YC's own engineering team cut sprint time in half and shipped 10x the work after this shift.
The agent needs to have read access to every single artifact that the company produces.

-
Coding goes to zero. Taste doesn't. Diana's clearest line: the cost of shipping code is collapsing, but the cost of knowing what's worth shipping is not. Evals are how taste gets compiled into a system that runs at agent speed. Generic benchmarks like MMLU tell you nothing about whether your product is actually helping the user.
-
The wedge is forward-deployed engineering. Salient (voice agents for loan servicing — closed top US banks), Happy Robot (logistics voice, Series B, 10x revenue in a year), and Reducto (document processing) all followed the same playbook: pick a painful workflow, embed inside the customer, and automate the manual labor that lives in spreadsheets, phone calls, and email.
-
Software engineering is at 49.7% of agent tool calls. Every other vertical is under 5%. Anthropic's agent autonomy data shows back-office, finance, healthcare, legal, and customer service barely touched. Diana's read: "There's room for hundreds and hundreds of AI unicorns waiting to be started."
Why I Watched This Lecture
CS153 is one of the few classes that gets actual industry operators to talk about systems-level shifts in real time. I watched this session because the previous YC playbook — raise a seed round, hire 10 people, build a SaaS — was breaking in obvious ways across our customer base at WebSearchAPI.ai. We were seeing six-person teams ship more software than 60-person teams from 2022. I wanted to hear Garry articulate why, and I wanted Diana's framework for thinking about it without falling into hype.
The talk delivers both. Garry's section is the most concrete description of agentic primitives I've heard — he names the actual files (agents.md, claude.md, context-now.mjs), the actual mistakes (latent space hallucinating timestamps because the model thinks it's in Greenwich), and the actual fixes (resolvers that load instructions on demand). Diana's section is the better strategic lens — the open-loop/closed-loop frame is the cleanest way I've seen anyone explain why "agentic" is a company architecture decision, not a tooling decision.
Why Is Markdown Now Code?
The lecture's first big claim, from Garry: markdown is the new code, and the new SAFE is a stack of markdown files. The SAFE in 2011 took a two-page legal document and turned it into the standard contract that funded thousands of startups. Anjney's framing in the intro is that we're now living through the same standardization moment for company formation, only at the agent layer.
What changed is that LLMs can do real work from instructions written in plain English. A skill file is "just a bunch of markdown" — Garry concedes that's what the haters say on Twitter — but the markdown can call deterministic code when the latent space isn't reliable enough. That hybrid is the unlock.
The SAFE was a legal instrument. What we're going to talk about today is actually code. And not just code — markdown is code.
The concrete example Garry uses: he wanted to coordinate seating at an 800-person YC dinner. ChatGPT can sort 8 people. It can't sort 800 — the context blows out and the model hallucinates. The fix isn't a bigger model. The fix is to write a skill that orchestrates the latent space (dossier lookups, vibe matching) and calls deterministic code (the actual graph-coloring assignment) where reliability matters. That pattern repeats everywhere in the new YC portfolio.
The piece I'd add: this is also why I think the "AI agent" wave finally stuck after three years of false starts. The 2022–2023 attempts treated everything as a prompt. The 2025–2026 stack treats prompts and code as peers, and the resolver layer is what lets you swap between them without bloating context.
💡 Expert Insight from James Bennett (Lead Engineer, WebSearchAPI.ai): We rebuilt our WebSearchAPI.ai retrieval pipeline along these exact lines in Q1 2026. Query intent classification stays in the latent space (it's a fuzzy, taste-driven decision), but the actual ranker, deduplication, and freshness filter are deterministic TypeScript with their own test suite. The hybrid cut our p95 result-quality variance by roughly 60% versus the all-prompt version we'd been running in 2024. Garry's 800-person dinner example is the same shape as the failure mode we hit in production: a single model trying to do both decisions blows out context on anything past a small N.
How Did Garry Tan Get to 100,000 GitHub Stars in Two Months?

Garry stopped coding around 2018 when he started Initialized Capital. He started again in December 2025 after seeing Steve Yegge's post claiming Anthropic engineers are roughly 1000x more productive than 2005 Googlers. He opened Claude Code, "ended up writing around a million lines," and shipped gstack and gbrain in the first half of 2026.
The traction is the part worth staring at. 87,000 GitHub stars in two months. 14,965 unique opt-in installations (real number is 2x+ once you account for telemetry opt-out). 305,309 skill invocations since January. 7,000 weekly active users. 27,157 real-browser sessions running Playwright automations — not toy demos. 95.2% success rate across all skill runs.
A six-person team can hit 10 million in revenue with just the things we're talking about today. For some of you, this is some astonishing good news.
Garry's most cited skill is office-hours, which is a distillation of how YC's 15 partners actually run office hours. The first version was four months of conversation transcripts compressed into something potent. He had to compress that another 90% before it shipped in gstack. The second most-used skill is plan-eng-review, which he runs about 20 times a day to drive his projects to 80–90% test coverage so he can ship to production without slop.
The pattern: pick a workflow you do constantly, freeze the best version of it as a skill, and use it like a junior coworker. The leverage isn't in any single skill. It's in the discipline of skillifying everything you touch.
What Are the Agentic Primitives Garry Tan Uses Every Day?

The primitives are stackable. Garry walks through them in roughly the order he discovered them, and each one solves a specific failure mode in the previous one.
| Primitive | What it does | Failure mode it fixes |
|---|---|---|
| Skill | Runbook in markdown that an agent (or human) can follow step by step | Latent space hallucinating instead of following a known procedure |
| Code-in-skill | A skill calls deterministic TypeScript when reliability matters | LLM guessing timestamps, time zones, math, or schema-bound data |
| Resolver | Master directory in agents.md that loads skill files only when needed | claude.md blowing past 40,000 tokens and degrading attention |
| Skillify | A meta-skill that turns a one-off success into a tested, evaluated, resolver-triggered, schema-versioned skill | One-off prompts that work today and silently break next week |
| CheckResolvable | Audits whether a new skill is unique or duplicates existing ones (DRY) | A thousand skills that all do the same thing slightly differently |
| LLM-as-judge eval | Tests that the resolver fires when it should and rates skill output quality | Skill exists but never gets triggered, or gets triggered and produces garbage |
| gbrain (3-layer memory) | Knowledge wiki + vector search + RRF fusion + typed knowledge graph | Pure grep fails at retrieving the right context |
The clearest illustration of the resolver pattern is Garry's context-now.mjs file. Claude Code, left to its own devices, will sometimes hallucinate the current time as 3 AM Greenwich because that's a stable point in the latent space. Garry wrote a tiny TypeScript file that returns the actual time, wrote tests for it, and wired it into his system so the agent never guesses. That's the whole pattern: every place where the latent space is unreliable, deterministic code takes over.
It's amazing how much you have to spend time getting this right. Turning it into a proper resolver means anytime you have to write to the change log, load changelog.md. Suddenly you don't need that in your context.
There's a personal taste signal in here that I want to flag. Garry mentions that gbrain is his schema right now — built for the way he files things in his own head — and that the v1.0 release needs a "dynamic ontology" so a journalist, a researcher, or a politician can each have a schema that matches how they think. That's the right design constraint. The reason most company knowledge systems fail isn't retrieval — it's that the schema reflects nobody's actual mental model.
💡 Expert Insight from James Bennett (Lead Engineer, WebSearchAPI.ai): The
context-now.mjsfailure mode is the single most-reported bug class I see in customer support tickets from teams wiring WebSearchAPI.ai into Claude Code workflows. The agent assumes UTC, queries our/searchendpoint with stale date filters, and confidently returns "no results" for current events. Our docs now ship a 12-linecurrent-contextskill that mirrors Garry's pattern — load it via resolver, never trust the model's wall clock. After we added that skill to the quickstart, "stale-date" tickets dropped about 70% inside two weeks. Karpathy's knowledge wiki post that Garry credits as gbrain's starting point is also the cleanest mental model I've found for thinking about how an agent's memory should be structured.
How Do the Agentic Primitives Map Onto a Company?
This is the slide that earns the lecture title. Garry's closing move before handing to Diana is to point out that the primitives he just described aren't only agent infrastructure — they're isomorphic to how human companies work.
| Agentic primitive | Company equivalent |
|---|---|
| Skill | Employee with a capability |
| Resolver | Org chart and filing rules |
| Brain repo location | Internal process / where information lives |
| CheckResolvable | Audit and compliance |
| LLM-as-judge eval triggers | Performance reviews |
Garry's commentary on this: when he was a Stanford undergrad, he had no idea why so many people in big organizations spent so much time on audit and compliance. At 45, building agentic systems and watching Skillify checks fail because resolvers don't trigger, he gets it. Systems get messy. CheckResolvable is the compliance function — and an agentic company that doesn't run it ends up with a thousand overlapping skills the same way a regulated company without compliance ends up with a thousand overlapping policies.
This is the part of the lecture that I think gets quoted in deck after deck for the next two years. The argument is short: if you accept that skills replace employees, then everything that makes a human org function — the org chart, the process docs, the audit function, the performance review — has an exact analog in the agent stack. Build them on purpose. Don't wait until they emerge by accident.
What Is an Open-Loop Company vs a Closed-Loop Company?

Diana borrows the open-loop/closed-loop distinction from control systems. In an open-loop system, error accumulates because there's no feedback. In a closed-loop system — think PID controllers in robotics — feedback is tight and error stays bounded. Most pre-AI companies are open-loop. Information lives in people's heads, DMs leak context, meetings go unwritten, decisions get made on vibes, and agents see roughly 10% of the actual state of the company.
A closed-loop company makes the opposite bet. Every workflow produces an artifact an agent can read: Linear tickets instead of side conversations, public Slack channels instead of DMs, recorded sales calls instead of memory, customer feedback in Pylon, docs in Notion. Once that's true, you can drop a Hermes-style agent into the org and have it suggest next actions because it has the full state.
In practice, we implemented this at YC with our engineering team. We're basically able to cut the sprint time in half and produce 10x the amount of work.
Diana cites Jack Dorsey's recent post on the agent organization for the structural implication: middle management was always a routing layer for lossy human-to-human information transfer. When agents can route, middle management collapses. What's left is three roles.
- IC builders — even non-technical hires now ship things. A salesperson can wire up their own pipeline of calls and follow-ups.
- DRI (Direct Responsible Individual) — borrowed from Apple. One person owns each outcome and orchestrates the ICs (and agents) needed to hit it. Often the founder.
- AI founder — lives at the edge of every tool, tries the new agent stack the day it ships, and brings the best primitives back into the company.
The numbers Diana cites are striking. YC portfolio companies are hitting $1M–$2M in revenue per employee. Public comps like Salesforce sit under six figures per employee. That's a 10–20x gap, and Diana's read is that it's the gap between open-loop and closed-loop architectures.
💡 Expert Insight from James Bennett (Lead Engineer, WebSearchAPI.ai): We made the open-loop to closed-loop switch internally at WebSearchAPI.ai in February 2026 and the lift is the most extreme I've seen from a single process change in eight years of engineering management. Three rules: every customer call gets transcribed and dropped into a per-customer Notion page; no DMs about anything that affects shipping (everything moves to public Slack channels); every code review comment lives in the GitHub thread, not a side conversation. Our Claude Code agents now read the full state and surface "this customer asked about X three weeks ago — your PR for Y partially addresses it" in standup notes. Diana's $1M–$2M revenue-per-employee number maps to what I'm watching happen at our own infrastructure customers: the ones generating those numbers have all completed the closed-loop migration. The ones who haven't are still hiring middle managers.
Why Is "Taste" the One Thing Agents Can't Replace?

The lecture's most-quoted single line will be Diana's: evals are taste made executable. Shipping code is going to zero. Knowing whether the thing you shipped is good or bad is what stays scarce. Garry has been making this point too — his cross-modal eval feature, which he's about to ship inside Skillify, runs the same input through Opus, GPT 5.5, and DeepSeek v4 and feeds the cross-rater scores back to the original sub-agent for the next iteration.
Coding — let's just call it shipping code — the cost of it is going to zero. But what is not going to zero is the taste to build something good. The taste to discern what's good or bad.
The corollary Diana makes explicit: generic benchmarks like MMLU don't tell you whether your product works. You need product-specific evals that grade for the things your users actually care about — did it follow the instructions, was the answer correct, did it preserve customer trust, did it hit the business goal, did it comply with domain rules. And those evals only exist if a human goes into the traces, labels what's right and wrong, and skillifies the lesson.
Garry's funniest framing of why you need cross-model evals: "Claude Code is my ADHD CEO. Codex is my nearly nonverbal 200 IQ CTO. I need both of them to do cross-modal analysis and then it ships with zero bugs." It's a joke about the personality of the two models, but it points at something real — different model families have systematically different failure modes, and running them against each other surfaces bugs neither would catch alone.
💡 Expert Insight from James Bennett (Lead Engineer, WebSearchAPI.ai): Cross-model evals are now the only kind of quality monitor I trust on our WebSearchAPI.ai ranking layer. We run every result page through Claude Opus, GPT-5.5, and DeepSeek v4 in parallel with a fixed rubric (relevance to query, source diversity, presence of authoritative domains, freshness alignment with query intent). When all three scores agree, we trust the ranking. When two agree against one outlier, we trust the majority but log the disagreement for human review. Pure single-model eval missed about 1 in 6 ranking regressions we caught later in customer complaints; cross-model dropped that to roughly 1 in 40. The cost is real — about $0.003 per query at our volume — but the per-regression cost in churn is much higher. Diana's "evals are taste made executable" is the cleanest one-line description of this whole workflow I've heard.
Where Are the One-Person Frontier Companies Getting Built?

Diana's closing case studies are three YC portfolio companies that hit 8-figure revenue inside a year. Each one followed the same playbook: pick a painful workflow, embed inside the customer, become the forward-deployed engineer.
- Salient — voice agents for loan servicing. Closed several of the top US banks. Founders had no finance background. They learned the workflow by shadowing.
- Happy Robot — voice agents for freight logistics. Closed a Series B last year. 10x revenue in 12 months. Embedded with freight forwarders to learn the trucker coordination workflow.
- Reducto — document processing. The hidden infrastructure win — every other agent that needs to read documents gets better when document parsing gets better, so improvements to Reducto compound across the ecosystem.
The founders of Salient or Happy Robot did not come from a finance background or logistics. They actually shadowed or took a job and learned the depths of everything that had to be done.
The framing for where the next decade of companies gets built is the Anthropic agent autonomy report, which Diana puts on screen.
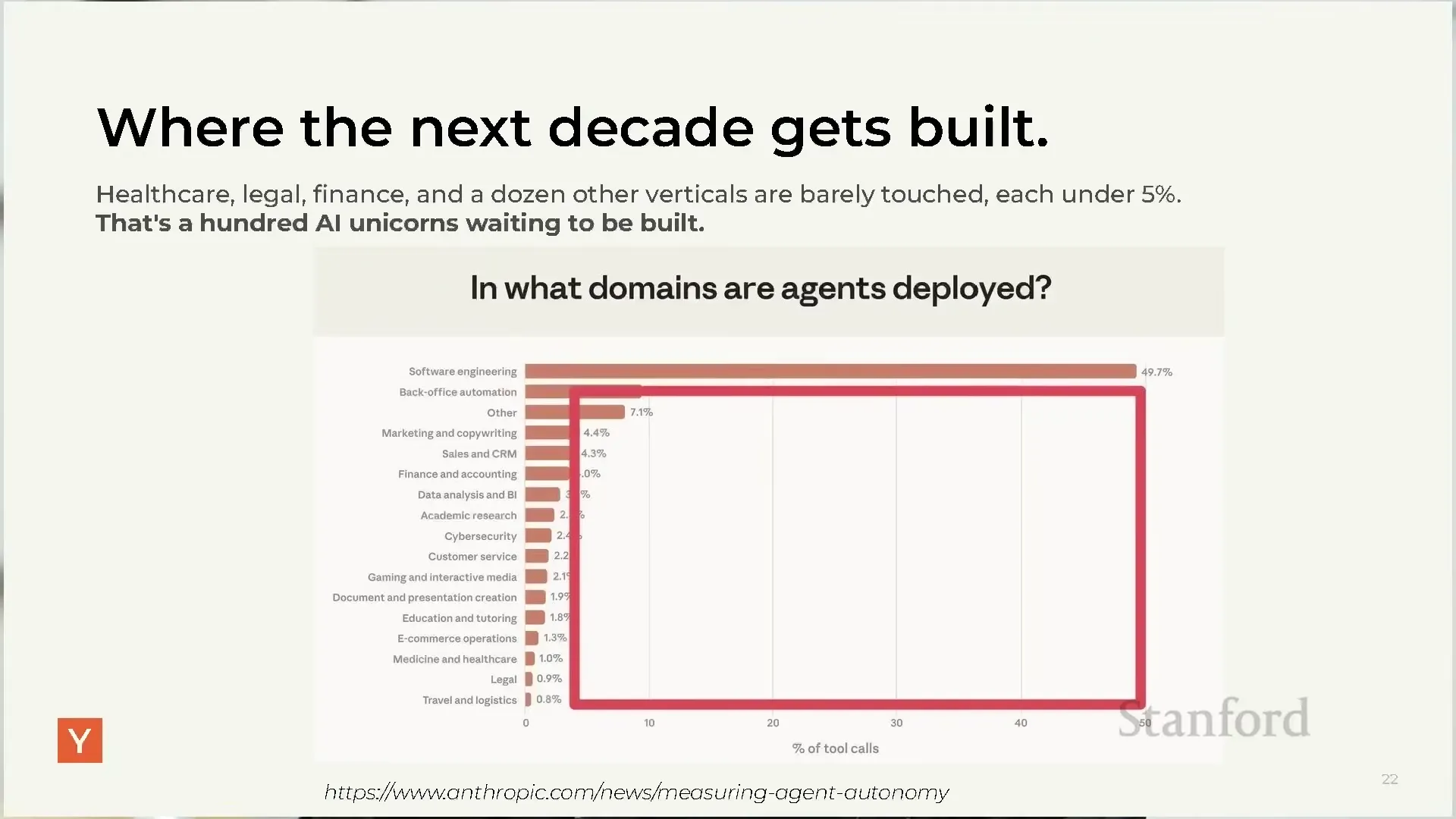
Software engineering is at 49.7% of all agent tool calls. Everything else is under 5%. Back-office automation, marketing and copywriting, sales and CRM, finance and accounting, data analysis and BI, academic research, cybersecurity, customer service, document creation, education, e-commerce, healthcare, legal, travel and logistics — each of those is a near-empty vertical with a complete agentic playbook now sitting in g-stack.
Diana's read: there are hundreds of AI unicorns waiting to be started, and the wedge is always the same — find a vertical, shadow the workflow, build the agent that automates it, deploy it as a complete solution, not a demo. Garry's coda: "We're at the first pitch of the first inning on the revolution."
Frequently Asked Questions
What is a "1000x engineer" and where does the number come from?
The number comes from a Steve Yegge post Garry cites at 11:29 in the lecture. Yegge claims engineers using AI coding agents are 10x–100x more productive than engineers using Cursor and chat-based assistants, and roughly 1000x more productive than 2005-era Googlers. Garry treats it as a useful exaggeration, not a strict benchmark — the real measurement that matters is whether you can ship something users will pay for. His personal proof point: rebuilding Posterous in 5 days on a $200 Claude Code Max plan vs the original 2 years and 10 hires.
What is "Skillify" in Garry Tan's gstack?
Skillify is a meta-skill that takes a one-off interaction with an agent and converts it into a permanent skill. The full ritual is 10 steps: write the code, write unit tests, write LLM evals for the skill file, write an integration test, add a resolver trigger in agents.md, run an LLM-as-judge eval, run CheckResolvable to confirm the skill isn't a duplicate, run an end-to-end smoke test, pick a schema, and commit it to the right place in the memory repo. Garry uses it roughly 20 times a day.
What is a "resolver" in Claude Code and why does Garry Tan call it the core of a great agent?
A resolver is a master directory (typically in agents.md) that tells the agent which skill file to load for which type of task. Without one, projects load all instructions into context at once — Garry shows the error message that fires when claude.md exceeds 40,000 tokens. With a resolver, the agent only loads the instruction file it needs (changelog.md when writing to the changelog, the executive-assistant skill pack when checking signatures), keeping context lean. Garry calls it the core of a great agent at 24:21 in the lecture.
How is Diana Hu defining an "AI-native company"?
Diana defines an AI-native company as a closed-loop system: every workflow produces a machine-readable artifact (Linear ticket, GitHub commit, Slack message, recorded call, Notion doc), an agent has read access to every artifact, and the agent uses the full state to suggest next actions and self-heal. The contrast is the open-loop org, where information lives in DMs, unwritten meetings, and vibes, and agents can see roughly 10% of state. YC's own engineering team rebuilt this way and reports cutting sprint time in half while shipping 10x the work.
How much revenue per employee do AI-native YC companies generate?
Diana cites $1M–$2M in revenue per employee for the AI-native companies in YC's portfolio. The closest public comp she names is Salesforce, where revenue per employee sits under six figures. That implies roughly a 10–20x gap between an AI-native org and a comparable traditional SaaS company — a gap Diana attributes to the open-loop/closed-loop architectural difference rather than any single tool choice.
What is the DRI role in an AI-native company?
DRI stands for Direct Responsible Individual — Diana borrows the term from Apple. In Diana's three-role model for an AI-native company, every outcome traces to one DRI who owns it end-to-end. The DRI orchestrates ICs and agents to hit the goal, but the buck stops with them. In an early-stage AI-native startup, the DRI is often the founder, and middle management as a coordination role largely disappears because routing is handled by agents instead of humans.
Which YC portfolio companies are examples of the "forward-deployed engineer" wedge?
Diana names three. Salient built voice agents for loan servicing and closed several of the top US banks via FDE pilots. Happy Robot built voice agents for freight logistics, closed a Series B last year, and 10x'd revenue inside 12 months. Reducto built document parsing infrastructure that improves every other agent that needs to read documents. All three followed the same pattern: pick a painful workflow, embed inside the customer, build the agent, and deploy the full solution instead of a demo.
Where is the white space for the next generation of AI startups?
Diana shows the Anthropic agent autonomy report on screen at 45:13. Software engineering is 49.7% of all agent tool calls today. Every other vertical — back-office automation, finance, sales and CRM, healthcare, legal, customer service, cybersecurity, education — is under 5%. Diana's read: hundreds of AI unicorns can be built in those verticals, and the playbook is the same forward-deployed wedge that Salient and Happy Robot ran.
Key Takeaways
- Agentic primitives are isomorphic to company structure. Skills are employees, resolvers are the org chart, the memory repo is internal process, CheckResolvable is audit and compliance, eval triggers are performance reviews. Build them on purpose.
- The Skillify ritual is 80% scaffolding and 20% code. If you only write the prompt and skip the tests, evals, resolver trigger, dedup check, and smoke test, the skill will silently rot. Garry's 10-step Skillify exists because those failures already happened.
- Closed-loop companies beat open-loop companies at 10–20x revenue per employee. Every workflow needs to produce an artifact an agent can read. DMs, unwritten meetings, and vibes are dead weight.
- Coding cost is going to zero. Taste isn't. Evals — especially product-specific, cross-model evals run against real user outcomes — are how taste gets compiled into a closed-loop system.
- The wedge for one-person frontier companies is forward-deployed engineering. Pick a vertical where 80% of the work happens in spreadsheets, phone calls, and email. Embed inside the customer. Build the agent. Deploy the full solution, not the demo.
- Software engineering is the only vertical with significant agent penetration. Every other industry — finance, healthcare, legal, customer service, back-office — is under 5%. The next decade of AI startups is being built in that white space.
This post is based on Stanford CS153 Frontier Systems | The AI Native Company: How One Founder Becomes a 1000x Engineer by Stanford Online, featuring Garry Tan and Diana Hu of Y Combinator, hosted by Anjney Midha of AMP PBC. Course site: cs153.stanford.edu.